
Guess what? There were TWO best papers at FAST ’07
I wrote about “Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You? (see Everything You Know About Disks Is Wrong). So it is equal time for the other the other “best paper” “TFS: A Transparent File System for Contributory Storage” (pdf) by James Cipar, Mark D. Corner, and Emery D. Berger of the U. Mass. Amherst Computer Science department. This is a great piece of work that I’d love to see people run with.
Think of it as SETI@home for data. A giant network-based data storage system that works in the background using what you aren’t to provide a world-wide storage resource. Cool.
OK, file system I get. What’s with Transparent?
Yeah, and contributory too.
Let’s start with contributory. It means a file system that uses disk blocks contributed by people on a network. You’d sign up your system and all the unused disk blocks on your hard drive(s) are contributed to this giant on-line file system, TFS.
“Stop right there!” I hear you say. “I don’t want all my unused disk storage sucked up by a giant data vampire!”
TFS is designed to work with contributory applications, such as folding@home, the protein folding app. You volunteer your machine and the app works in the background. These apps already understand that machine cycles can go away at any time, so they correctly handle lost files too. I believe TFS could be adopted to other applications as well – more on that later.
Performance and capacity
Using free disk space on nodes across a network is not a new idea. The problem is getting enough storage to make it worthwhile, while not irritating users. One idea is simply to take over a percentage of the node’s disk. In effect that simply adds another file and what if the user suddenly needs that space? Also, it limits the capacity contribution to far less than it could be with a more dynamic allocation.
Another idea is to watermark the contributed capacity, so when the node wants that capacity it has to delete the data first, setting off data replication on another node. This results in higher capacity contributions and much greater overhead – and a big performance hit as each write becomes a delete-first then write. Also, watermarking reduces a disk’s contiguous free space, hastening fragmentation even before the contributed storage needs overwriting.
Here’s where the Transparent comes in
TFS uses free space on your drive, true. It also allows the host system to overwrite any TFS blocks at any time for any reason. TFS is “transparent” to the host operating system: the OS doesn’t know or need to care about any TFS occupied blocks. As a result TFS has little impact on host system performance. If the host needs a big block of contiguous space, it can take it without worrying about TFS.
Some trade-offs
TFS requires five different block states (see state diagram) to do its magic. It takes more work and larger indices to keep track of the states, which seems a small price to pay for good host performance and more contributed disk space.
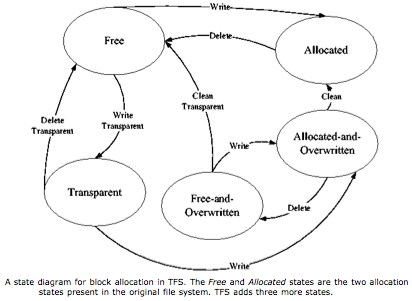
TFS does write its metadata as non-transparent files on the contributing system. Losing metadata is costly for TFS and the capacity used minimal for the host. Another, possibly more costly trade-off is that TFS does not allow the overwriting of open TFS files. If TFS files are large or many are typically kept open, that might be a problem. Intelligent application design should eliminate either problem.
Storage capacity, bandwidth and reliability
All storage is flaky so all storage relies on replicating content to assure availability. The flakier the storage the more replication is required. In TFS storage flakiness has more sources than usual:
- TFS data can be overwritten
- The disk or node can fail
- The network can fail
The authors analyze how much replication is required to achieve 0.99999 – five nines – availability. The issue basically boils down to how reliable each of the elements is, with the added fillip that a lot of block, disk or node churn will impact network bandwidth requirements.
Net net, TFS is well-suited to highly available private networks, such as campus-wide corporate nets. It also works well with stable groups of users. Trying to mine the laptop space of a group of road warriors, always up and down on the net, is TFS hell. Good node availability reduces network bandwidth requirements and increases the contributed storage. The flakier the nodes the more bandwidth is required for replication. Node and network stability helps TFS do its best work.
How well does it work?
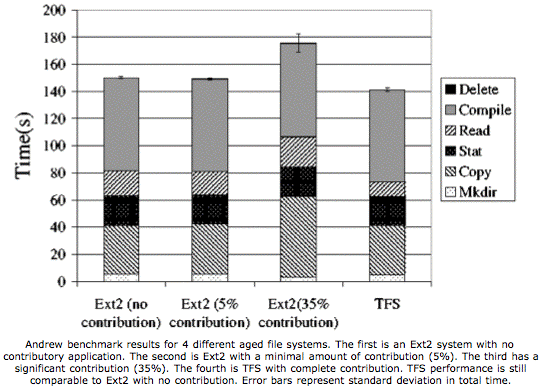
The authors ran a number of tests on a small number of systems. Overall, they found it performed well. They tested four Linux systems with the Ext2 file system at varying levels of capacity contribution (0%, 5%, 35%) against a TFS system at 100% contribution. They found the TFS system performed most like the EXT2 system with 0% contribution. Furthermore, TFS provided 40% more capacity than the other contribution systems it was compared with. The figure gives the gory details.
The StorageMojo take
The TFS prototypes are implemented in the kernel, so this won’t be available to the average Linux user soon. Yet as the world’s broadband build-out continues and powerful computer systems propagate, there will be huge amounts of storage capacity available for contribution.
Once TFS or something like it has kernal support, the problem shifts to engaging large numbers of stable people to contribute. Social networking will solve that problem.
Finally, I wonder if TFS could be combined could be combined with Cleversafe’s open-source distributed storage system. Cleversafe enables public networks to store private data securely. If the two could be combined it would be possible to securely store private data on contributed storage. A group of musicians or artists could create a secure private storage system for their works in progress without having to worry about offsite backup.
Just a thought.
Comments welcome, especially if you have another idea. Moderation turned on to encourage you to find your own cheap car insurance.
Diagrams extracted from the paper along with everything else I know about TFS.
Professor Corner wrote and said that you can download the prototype source code right here. Let me know what you think if you look at it.

In academia, there have been quite a few projects on distributed file systems/content distribution systems. The most famous one is the Planet Lab ( still operating ): http://www.planet-lab.org/, which is more for computing not for storage. the Planet Lab is contributory: members ( mostly academic ones ) contribute their resources (CPU, storage, network bandwidth ) and then can use the system to conduct various tests. On storage side, the one I like is the LoDN: http://promise.sinrg.cs.utk.edu/lodn/, which I believe is not being developed any more. One thing good about LoDN is it operates at application level, not kernel level, which means it is easier to deploy. Then, again, any P2P tools can be rather easily adapted for persistent storage purposes. One common problem for any contributory storage systems is their stability. Each node has to be relatively stable ( accessible ) to keep the whole system usable. So I see the potential of this type of systems is for a large institution use, not for very loose Internet use, unless for not so important movie files, which it does not hurt if you get it today or 1 month later.
As of Cleversafe, again, I think they have done a good marketing. But all the basic components are already in LoDN ( I have to disclose I am in no way related to the LoDN project, which has not been a famous project at all. ) Users of Cleversafe, or any similar systems, should NOT have any illusion that data stored there is secure. The reason is very simple: the system has to provide an interface for a legitimate user to retrieve their data without worrying about which piece of data is stored on which node. Thus an attacker can simply use the same interface after assuming the legitimate user’s credentials, that is usually how attacks succeed. So without further cryptography-based measurements, this type of system is not secure at all.
For some reason I am reminded of Mojo Nation from the good ol’ P2P days: http://en.wikipedia.org/wiki/Mnet
Prof. John,
I’m somewhat confused by your argument against the security of Cleversafe’s architecture. Cleversafe’s client authentication is basically the standard RSA public-private key exchange used by SSH and many other systems in addition to a symmetric encryption cipher for the bulk data encryption. Thus, I don’t understand why you suggest that this type of system is not secure at all.
I do agree that the weakest point in their architecture lies in compromising a user’s account and authentication/encryption keys, but I’m not sure of a good way to get around this. A user’s private encryption keys would be kept secure on their client machine separate from the grid and protected with a passphrase. Without having the private keys, an attacker would have to break the authentication process to receive access to a majority of the encrypted data slices and brute-force the encryption of everything (mathematically improbable).
Reference: http://www.cleversafe.org/wiki/Grid_Design#Encryption
Disclosure: I am not affiliated with the Cleversafe company nor open-source project, just a curious onlooker.
Hi, Mathrock,
What I tried to say was security does NOT come from the distributed architecture of Cleversafe type systems, rather from other traditional cryptography based measurements. It is very risky to think since my data is distributed over different nodes in pieces and not all the nodes will be compromised, thus my data is secure. If that is impression this type of systems wants to give ( see a previous blog here: http://storagemojo.com/?p=120, I don’t know whether this was Robin had in his mind with his understanding of Cleversafe ), then it is wrong.
Disclosure: I am not against any systems, Cleversafe or RealCleversafe …
Since Security is a “Many-Splendored Thing” I believe it would help to separate out what the risks are and the solution for that risk.
Intrusion of Information for purposes of exploitation is criminal.
Solutions are hardening of facilities, Identity Management, and local solutions, like encryption of Information Storage Units of Technology.
Intrusion by unauthorized users of Information that is deemed private is an invasion of privacy. Identity Management solves this.
Distribution of Information to reduce or remove risk of loss is Information Integrity, Disaster Recovery and Business Continuity.
If the Distributed Information is geographically dispersed it has the least risk of loss from Disasters.
It may be at higher risk to local exploitation.
These Security Risks could be called Types I, II and III. How these Types are assigned and weighted is purely a local option based on what the Information owner knows about the Value of the Content of the Information they own. There is now a Type IV to comply with regulations like HIPPA and Sarbanes-Oxley. Types I, II and III solutions will handle Type IV Security but do not provide the “clear” audit trail required.
A couple of easy yardsticks to determine Types are:
1) Which of your Stored Information generates 80% of your gross revenue?
2) Which of your Stored Information, should you lose it, will put you out of business?
I once heard a lot of talk about virtualization.
Now I hear a lot of talk about distributed architectures.
Both of these highlight the woeful inadequacy of existing Security from Intrusion exploitation and privacy invasion.
Both of them offer a great deal of promise for Information Integrity, Disaster Recovery and Business Continuity.
So is Step 1 virtualization or a distributed architecture to safeguard against Disasters and promote Information Integrity and Business Continuity?
Or true, meaningful Identity Management to secure against Intrusions?
Depends on your needs…
If you look at bvn’s Information stack (IS) Strategy, the more innovative a solution, the higher the risk.