
Storage is cheap and getting cheaper. But at scale it will never be free.
At scale – today, petabytes; in a decade, dozenss of petabytes – even a few per cent savings amounts to real dollars. Strategies that made sense 10 years – such as triple replication – are less viable as capacity continues to grow 40-50% a year.
Thus the growing interest in advanced erasure codes for large stores. (If you want a 5 minute visual intro to them this video white paper I did for Amplidata on erasure codes will help.)
The innovation
At this weeks Storage Developer Conference Cheng Huang, a developer working on Windows Azure – Microsoft’s cloud service – presented Erasure Coding in Windows Azure Storage (available only to attendees so far).
Cheng’s (and colleagues) twist on existing erasure codes is what he’s dubbed Local Recovery Code or LRC. While standard erasure codes are computed across the entire storage stripe, LRC computes both global and local codes.
Coding across the entire stripe is fine as long as nothing breaks and loads are balanced. But break and unbalance they do – and standard codes become expensive.
Google’s GFS II – among other cloud infrastructures – uses triple replication to ensure data availability. That works, but the WAS team realized that single failures are much more common than double or triple failures – and that optimal coding could dramatically reduce single failure reconstruction overhead.
That’s important because Azure uses reconstruction to avoid hot storage node read latency to improve performance. When a node is unavailable or hot an Azure 12 storage server stripe requires 12 reads and 12 data transfers to rebuild data.
The LRC advantage
LRC does it differently. LRC breaks a 12 storage server stripe into 2 groups of 6. To survive 3 failures, LRC calculates 4 codes: 2 across all servers; and 2 across 6 server subsets.
Here’s a diagram:
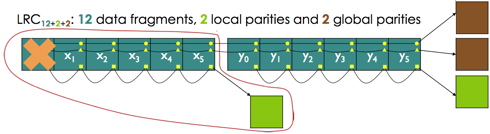
In the common single-node failure scenario, reconstruction requires only half the I/Os. And not only does an LRC12+2+2 protect against all triple failures, it also will recover from 86% of quad failures.
Compared to Reed-Solomon coding, LRC can be tuned for either lower overhead at the same level of redundancy, or more redundancy at the same overhead:

The StorageMojo take
At scale even small improvements yield large savings – and LRC is no small improvement. More importantly, at scale providers can support the research needed to make these improvements.
This kind of work would make no economic sense in most enterprise data centers. But it points to the inexorable pressure that cloud providers are putting on corporate IT to improve their efficiency and effectiveness.
Kudos to the Azure team for this work.
Courteous comments welcome, of course. While the SDC slides aren’t available online yet, Cheng et. al. have a Usenix paper and slides available here.

“Compared to Reed-Solomon coding, LRC can be tuned for either lower overhead at the same level of redundancy, or more redundancy at the same overhead”
Overhead? Redundancy? I find MS “reconstruction read cost/storage overhead” clearer.
And the chart makes little sense anyway, it shows 2 negatives w/out the (variable) positive – chance of successful recovery. I guess they wanted people who don’t read the entire piece to think that at the same overhead both algorithms have equal chance of recovery. This coupled with starting charts at 1.2…I think you would do better by fixing the chart or at least adding arrows “careful, they cheat” at it because the way it is it’s unserious.