
The transition to a storage-centric world continues. Billions of internet devices are driving exponential scale-up challenges. A3Cube’s Massively Parallel Data Processor (MPDP) may be the most comprehensive response yet to that reality.
It makes less and less sense to move massive amounts of data and more and more sense to move the computes and network closer to where the data lives. This is the core architectural problem.
But as with any potentially category-busting product, explaining it is a problem: it doesn’t fit into our common categories. The MPDP is a network, a fabric, a storage system and an enabling foundation for analytical apps.
That’s a key point anchoring the following discussion. The MPDP is intended to interoperate and integrate with existing apps and protocols, such as MPI and Hadoop.
Their product consists of several pieces. Taking it from the top.
The software overlaying the hardware infrastructure is the Build your Own Storage or ByOS. Based on Linux it manages the underlying structures needed for the single namespace parallel filesystem: a striper engine; and a data plane network.
The striper engine works across all nodes and eliminates the need for metadata synchronization by offloading metadata updates to local file systems. All I/O is replicated across multiple nodes for robustness and scalability. This enables parallelization and integrates with the dedicated parallel hardware architecture, while eliminating the need for RAID hardware.
The data plane is a dedicated internode network based on a traffic coprocessor – the RONNIEE Express Fabric – designed to provide low latency and high bandwidth for up to 64,000 nodes, without expensive switches, in a sophisticated mesh torus topology. User traffic remains on a front-end network.
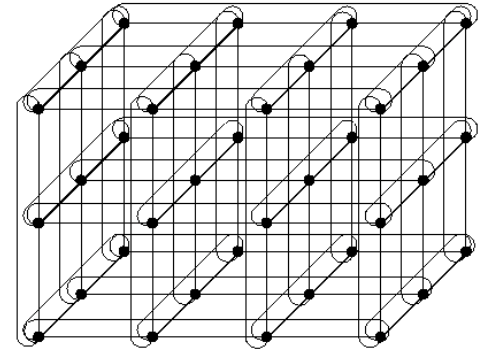
Graphic courtesy of the University of Wisconsin
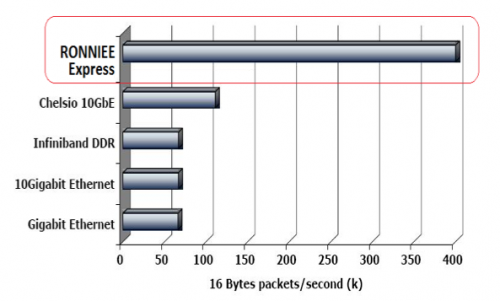
The data plane network provides an “in-memory network” where internode accesses appear to the local node as a local memory access. No network stack and a globally shared memory architecture for maximum performance that is 6 to 8 times faster then Gigabit Ethernet or DDR Infiniband according to A3Cube.
The RONNIEE interface card is part of the storage and compute node. The node is a server loaded with as much go-fast hardware – SSDs, cores, other coprocessors, Infiniband, 10GigE – as you can afford, plus your favorite apps. A3Cube also provides software modules for system control, scheduling and computation.
The StorageMojo take
Congratulations to A3Cube for coming up with a creative answer to the question of massive scaling of massive data. The architecture makes sense.
Concerns include A3Cube’s HPC focus, a technical issue with PCIe 3, financing and competition.
- HPC has been the graveyard for much great technology for two reasons: it’s much more fun – i.e. distracting – for dev teams than typical commercial markets; and, the highly variable spend thanks to the national labs. Not many commercial products come out of an HPC focus. Big data – including some HPC – is a better focus.
- The RONNIEE Express runs on PCIe 2.0 but not on PCIe 3.0 due to a device enumeration issue. But they expect to be able to support PCIe 4.0 whenever that comes out.
- Funding. A3Cube has been privately funded to the tune of about $1 million, and they need a more to go big. I don’t see investors funding an HPC startup.
- Competition. PLX Technology is already out there with not-as-scalable PCIe 3.0 fabrics. Not as elegant, but available now.
None of these should be deal killers. A3Cube’s issues are fixable with money and time and I hope they get both.
Their storage-centric approach and fast mesh architecture feels right. Fundamental architectural innovation is still alive and that’s a very good thing.
Courteous comments welcome, of course.

This looks like an interesting combination. On the hardware side, it reminds me of SiCortex (at the fabric level) and Dolphin (API). On the software side, it’s not all that dissimilar from GlusterFS. It would really be interesting to see something more than a hand-wave about some of the details, because several of the pieces are pretty serious projects in themselves.
* How to build that “File System Aggregator” with fully autonomous self-heal, snapshots, etc.
* How to manage that fabric, detect and route around faults.
* How to physically build something that’s dense enough to be interesting, without blowing power/cooling budgets.
* How to package it all up – all of that hardware plus what amounts to an entire Linux distro plus integration with the target apps – in a way that can sell.
$1M in funding is absolutely nothing for a project of this magnitude. Based on my own experience at companies doing similar things, getting something like this done in less than that *per month* and/or less than two years would be quite a stretch.
I also share your concern about being in the HPC market. That’s a decent place to make a name, but a terrible place to make any money. The really big labs/oil/bio folks will drag things out forever until they see some traction down-market, and the smaller fry are just plain hard to find (so ramp up that sales force). Maybe with an AAA-list executive team there’d be a chance.
Dear Sir.
I have interest in your RONNIEE Express, Could you provide more details? We are under investigation on the next generation Rack Server architecture for our product. Currently ,we plan to use PLX solution (PEX9797) and it is still under study. If you could share more better solution ,It will be appreciated.
1> The plan/schedule for RONNIEE Express which support PCIe 4.0
2> What’s the main difference between “RONNIEE Express” VS “PLX Technology” , why PLX ” Not as elegant”
Could you share more details if possible ?
thanks & Regards