
One of the decade’s grand challenges in storage is making efficient advanced erasure coded object storage (AECOS) fast enough to displace most file servers.
Advanced erasure codes can give users the capability to survive four or more device failures – be they disks, SSDs, servers, or datacenters – with low capacity overhead. By low I mean 40% over the net stored data, rather than the 3x replication default for many object stores today.
Advanced erasure codes are capacity efficient, but at a price: computational and read latency overhead. Accessing the data requires a lot of processing, which is why most of these codes are used for archives, not active data.
Yet as data volumes rise faster than either areal density grows (for disks) or cost-per-bit drops (for SSDs), capacity efficiency will become critical. Despite multiple variables and leverage points, there is a growing need for capacity efficient storage with at least good, and preferably great, performance.
Hitchhiker
Since CPUs and networks are not getting (much) faster, the obvious place to look for the needed performance improvements are in the algorithms underlying advanced erasure codes. In the paper A “Hitchhiker’s†Guide to Fast and Efficient Data Reconstruction in Erasure-coded Data Centers, K. V. Rashmi1, Nihar B. Shah1, and Kannan Ramchandran of UC Berkeley, and Dikang Gu, Hairong Kuang, and Dhruba Borthakur, of Facebook, present
. . . Hitchhiker, a new erasure-coded storage system that reduces both network traffic and disk IO by around 25% to 45% during reconstruction of missing or otherwise unavailable data, with no additional storage, the same fault tolerance, and arbitrary flexibility in the choice of parameters, as compared to RS-based systems. Hitchhiker “rides†on top of RS codes, and is based on novel encoding and decoding techniques. . . .
Piggybacking
The unintuitive part of Hitchhiker is that it builds on top of existing Reed-Solomon codes. So how does adding more data to an existing code make it more, rather than less, efficient?
At this point, those with a professional interest should download the PDF for detailed explanation. Essentially, the piggyback framework uses finite field arithmetic to add one byte of data to impart new properties to the underlying RS code.
These added properties can be designed to achieve different goals. The team focussed on reconstruction efficiency.
The authors present three different codes to demonstrate the concept and to test for production efficiency. Two of the codes use only low-overhead XOR operations, while the third – and most efficient – requires complex finite field arithmetic.
Test implementation
The team implemented their algorithms in the Hadoop Distributed File System (HDFS), which is widely used at Facebook. They built on the HDFS-RAID mmodule using RS codes as normally deployed in Facebook infrastructure. Here’s a diagram of what they implemented:

Click to enlarge.
Results
The team evaluated both computation times for encoding and degraded reads and read times for degraded reads and recovery. As expected, the additional computation overhead for encoding the different Hitchhiker variants is higher than straight RS codes.
Bottom line: substantial improvement in read times over traditional RS codes:
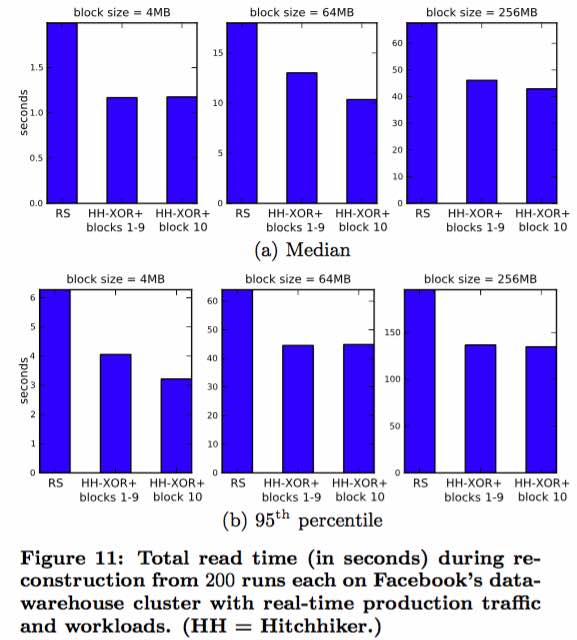
Click to enlarge.
This graph compares encoding times:

Click to enlarge.
The StorageMojo take
Most files aren’t accessed more than a handful of times. So why put them on costly high performance file servers?
Better to use commodity object storage with advanced erasure codes to get lower cost and higher availability than legacy active-active file servers can provide. Of course, but the performance penalty for advanced erasure coding has been a problem, as Cleversafe and others found.
Nonetheless, this paper demonstrates that significant progress is possible. Expect a decade of stepwise enhancements until AECOS displaces the vast majority of enterprise file servers.
Courteous comments welcome, of course. AECOS is a terrible acronym. Anyone have a better idea?

In my experience, part of the problem is the bottleneck(s) introduced at the storage (i.e. SAS/SATA) or even the network layer(s). That is, the CPU can and may be more idle or under utilized when distributing data across multiple drives or across multiple nodes in a network. This leaves room for additional processing which can include in-line data compression. Less data data across sent across the lines means less data to generate erasure code for and less data to eventually persist to disk. Some vendors, such as Pure Storage already practice this (out-of-box).
My (admittedly limited) experience and research into the subject is roughly in line with Petros. That the actual encoding at the CPU is generally not the bottleneck, but instead that the network tends to be, especially when you have really “wide” codes, e.g. 17/20 causing tons of traffic across many storage nodes for every request. I may be recalling incorrectly, but I think the hitchhiker codes were reducing the amount one had to snarf over the network to reconstruct.
I also remember a few years back TCP throughput collapse being an issue in striped/EC systems with (I think, don’t hold me to it) buffers overflowing and causing packet drops when you get a large pile of largely synchronized traffic getting centralized. Unsure if this is at all still an issue though.
It will be interesting to see, however, if we keep improving networks if the bottleneck does move to the CPU for encoding/decoding.
I suggest COST – Coded Object STorage