
Maybe you saw the hype:
Symbolic IO is the first computational defined storage solution solely focused on advanced computational algorithmic compute engine, which materializes and dematerializes data – effectively becoming the fastest, most dense, portable and secure, media and hardware agnostic – storage solution.
Really? Dematerializes data? This amps it up from using a cloud. What’s next? Data transubstantiation?
Patents
I haven’t talked to anyone at Symbolic IO, though I may. In general I like to work from documents, because personal communications are low bandwidth and fleeting, while documents can be reviewed and parsed.
So I went to look at their patents.
Fortunately the founder, Brian Ignomirello, has an uncommon name, which makes finding his patents easy. There are two of particular interest: Method and apparatus for dense hyper io digital retention and Bit markers and frequency converters.
The former seems to have had a lot of direct input from Mr. Ignomirello, as it is much easier to understand than the usual, lawyer-written patent. How do patent examiners stay awake?
The gist
There are two main elements to Symbolic IO’s system:
- An efficient encoding method for data compression.
- A hardware system to optimize encode/decode speed.
Encoding
The system analyzes raw data to create a frequency chart of repeated bit patterns or vectors. These bit patterns are then assigned bit markers, with the most common patterns getting the shortest bit markers. In addition, these patterms are further shortened by assuming a fixed length and not storing, say, trailing zeros.
Since the frequency of bit patterns may change over time, there is provision for replacing the bit markers to ensure maximum compression with different content types. Bit markers may be customized for certain file types, such as mp3, as well.
Optimizing
Symbolic IO’s patent for digital retention discusses how servers can be optimized for their encoding/decoding algorithms. Key items include:
- A specialized driver.
- A specialized hardware controller that sits in a DIMM slot.
- A memory interface that talks to the DIMM-based controller.
- A box of RAM behind the memory interface.
- Super caps to maintain power to the RAM.
Lots of lookups to “materialize” your data, so using RAM to do it is the obvious answer. Adding intelligence to a DIMM slot offloads the work from the server CPU.
Everything else is normal server stuff. Here’s a figure that shows what is added to the DIMM socket.
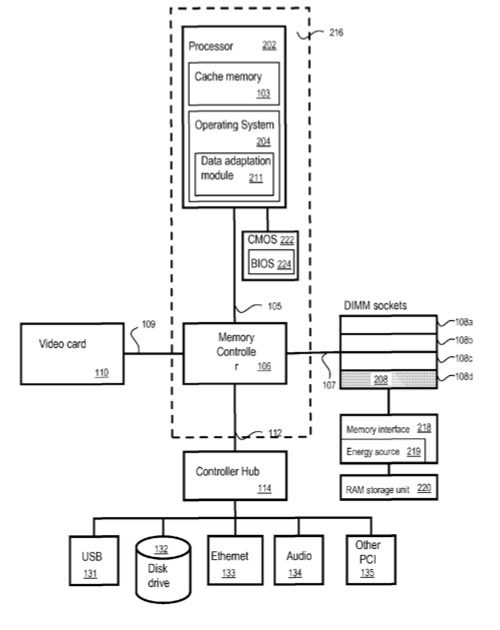
Diagram showing where Symbolic IO adds hardware to a server.
The StorageMojo take
Haven’t seen any published numbers for the compression ratio, but clearly such a system could far exceed Shannon’s nominal 50% compression. I can even see how it could further compress already compressed – and therefore apparently random and uncompressable – bit streams.
Reconstructing the data from a cache kept in RAM on the memory bus to achieve extreme data rates would be possible.
The controller in a DIMM slot is genius – and it won’t be the last, I’m sure. That’s the fastest bus available to third parties, so, yeah! Super caps for backup power? Of course!
Concerns? Much depends on the stability of the bit patterns over time. Probably a great media server. The analytical overhead required to develop the dictionary of bit patterns could make adoption problematic for highly varied workloads. But who has those?
Also, all the data structures need to be bulletproof, or you’ve got very fast write only storage.
Marketing: pretty sure that “dematerialize my Oracle databases” is not on anyone’s To Do list. Love to see some benchmarks that back up the superlatives.
But over all, a refreshingly creative data storage architecture.
Courteous comments welcome, of course.

Call me highly skeptical, but I don’t see anything eye-opening. I won’t claim to be a data compression expert by any means, but after a quick read of your description and the patent, I take it to be a variant of the classic compression algorithms.
Again, the skeptical side of me says that Mr. Ignomirello has spent the last 9 years as a technology executive, has no apparent math background, no published research in the field, and his other patents cover rack ears, disk drive trays, and integrating a cell phone into a car backup mirror to create a heads-up display. It’s highly improbable, though not impossible, that’s he’s come up with a novel algorithm that provides better compression.
Using the DRAM interface for the compression coprocessor is, possibly, a novel idea. However, general purpose processors and server mother boards are not designed for DRAM-based coprocessors. I highly doubt you can supply or draw more than a few watts through the DRAM socket, making it nearly impossible to support a coprocessor subsystem powerful enough to make an impact on performance.
On a $/operation and $/watt basis, I highly doubt a DRAM interface based coprocessor is cheaper than an additional core in the general purpose CPU.
If it’s necessary to use a coprocessor, we already have production hardware — the graphics co-processor using the PCIe bus. In fact, the Nvidia Titan X Pascal would be highly suited to the job: 3584 coprocessor cores, 12GB dedicated memory, 11 teraflops, 250W all for just $1200 retail.
I believe that Mr. Ignomirello is a competent executive and excellent marketer. But Symbolic IO suffers from the classic startup problem of marketing the “how we do it” rather than “what problem we solve for you”. Given the ever decreasing price per unit of storage, storage capacity is not the problem most companies are looking to solve when evaluating a new solution.
I am not so sure that you want compression in the DRAM rather than in the CPU itself.
Memory bandwidth is a limiting factor in some server applications and it definitely is in GPU applications; GPU throughput for games is increasing faster than memory bandwidth so texture compression is a BIG deal.
In general there are a lot of interesting ideas floating around the issue that arithmetic coding beats the crap out of branch predictors since if an arithmetic coder is doing it’s job, the 0/1 decision is not predictable. There is lots of room for clever ideas, even patentable clever ideas, around this — not just from the viewpoint of saving $ on storage, but from the viewpoint of pure speed plus the benefit of moving up the memory hierarchy.