
I came across this simple – too simple? – flash performance benchmark on an anonymous blog named DelayToleraNt.
The benchmark is
a Java program that creates random data (in chunks of kilobyte) and writes the data to a file. For comparison I ran the same program with the cheapest Intel based MacBook available using Java 1.4. I used same source level and same Java binary that I used on N800 running Java CDC.
So the comparison does not measure only storage performance, but also Java. Anyways, storage performance counts often only when some application is using the storage, and this application might as well be written on Java. In the tests, each size of file was created consecutively 10 times and average was calculated. For file size of 0 kB we measured only time to create an empty.
The flash didn’t do so well:
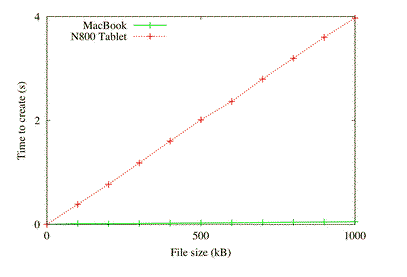
The author states he wants to do more tests combining download speeds with file creation times as well as testing an iPhone. That will be interesting.
The StorageMojo take
One benchmark is not enough to generalize from, so I won’t. If this is a consistent issue I have to wonder at the impact on mobile device user experience.
Comments welcome. Can someone try to replicate the results?
Addition: Another interesting performance topic is explored in A look at MySQL on ZFS by John David Duncan, a consulting engineer with MySQL Inc., that compares the performance and management of MySQL on UFS and ZFS.
The money quote:
ZFS introduces remarkable ease and flexibility of administration, without any real cost in performance. At its worst, in these tests, ZFS performed almost as well as UFS with Direct I/O. With InnoDB, the ZFS performance curve suggests a new strategy of “set the buffer pool size low, and let ZFS handle the data buffering.” I did not test Falcon, since it was not yet in Beta when I ran the benchmarks, but a similar strategy for Falcon on ZFS might be to concentrate on the row cache but minimize the page cache. And although double-buffering problems are clearly visible in this ZFS performance curve, even with those problems at their worst, ZFS still outperformed UFS. The real reason for the good performance on this benchmark is not clear — indeed, every workload will be different — but the ZFS I/O scheduler, the Sun engineers paying attention to database performance, and the ZFS bug fixes contributed in recent (late 2007) releases of Open Solaris seem to be adding up to something good.

I gather DelayToleraNt doesn’t handle too well general *NIX principle to deal with small and simple tools, And he seems to totally ignore opportunities of the dd and /dev/urand and /dev/null on Linux platform 😀
Since you saw fit to reiterate your link to Duncan’s to all appearances utterly incompetent ZFS/UFS performance comparison here, I guess I should restate my observations about it here:
As for the comparative analysis that you cite, the major conclusion one can draw is that for MySQL ZFS’s main advantage is in eliminating the need to use a more contemporary file system like XFS or JFS (rather than a mid-’80s design like UFS) and an underlying RAID to distribute load (though had MySQL used ZFS’s RAID-Z with a parallel workload they would very likely have found that the conventional RAID had a significant performance advantage over ZFS). That said, ZFS is indeed somewhat easier to manage than such a combination (though whether it’s *significantly* easier to manage will vary with the installation) and offers the “small performance gain [that] can be obtained†by disabling InnoDB’s doublewrite buffer (though pays a significant penalty for this when a table must be scanned sequentially, since ZFS’s write-anywhere policies severely fragment the table file – funny how that didn’t get mentioned, though it’s possible that InnoDB, unlike more serious databases, just doesn’t bother to try to maintain its tables in scan-optimized order).
It’s particularly significant that as InnoDB’s own buffer pool size increased, any ZFS advantage disappeared – because what ZFS was being compared against was UFS direct I/O (i.e., no UFS buffering at all). Therefore, ZFS was getting the use of all the RAM that InnoDB did *not* use for its own buffers, while that RAM was just sitting idle during the UFS tests: no wonder ZFS looked better than UFS at low InnoDB buffer sizes.
And then, in response to your resulting query:
The reviewer explained clearly why one *normally* disables UFS caching: “Storing two copies of the data effectively cuts the machine’s RAM in half.†In other words, UFS’s cache *normally* takes up RAM that could much more effectively be dedicated to InnoDB’s cache (having one large cache is far more effective than using an equal amount of RAM divided between two caches, one in front of the other). However, he then disabled the UFS cache *without* giving the RAM thus freed up to InnoDB’s cache, while allowing ZFS full use of the RAM that InnoDB’s cache wasn’t using, thus (whether deliberately or due to simple brain-fade) creating an apples-to-grenades comparison that UFS could not possibly do well in save when most of the RAM was given to InnoDB (at which point – mirabile dictu! – UFS pulled ahead of ZFS).
– bill
I’m not sure that the Mac vs N800 write test makes any sense given the massive variation in the systems being tested. If you want to perform a comparison which was more reasonable why not just test a USB stick (or one of those card readers) against a USB hard disk on the Mac? As it stands you are comparing the differing filesystems (I would suspect the Mac was using HFS+ whereas the N800 was using JFFS) operating systems (OSX vs Linux), controller connectivity, Java implementations, caching polices (the list goes on and on) all at the same time. You will never be sure which components are slowing you down the most or by how much…
What I found interesting about the post was the N800 performance. Is the N800 representative of all handheld flash devices? Who knows? The significance is that if mobile content developers and distributors are expecting PC-like storage performance and getting the N800 instead, consumers may not like it.
Bill, the article also referred to UFS’s read-ahead policies as another reason to go to direct IO. Care to address that?
Robin
I already did address it, Robin, by observing that this is one of the drawbacks of using mid-80s technology rather than something more recent like XFS or JFS (or even ext2/3).
It’s really easy to look good against an opponent of your own choosing using rules that arbitrarily (and significantly) penalize it. Unfortunately, it also appears to be really easy to snow people like you by doing so: even after the details of the scam have been exposed, you’re reluctant to accept them.
– bill
Perhaps I should have responded more specifically, though my general observation above stands.
Any well-designed contemporary file system won’t read ahead unless either the disk is otherwise idle (in which case reading ahead costs nothing – though the disk itself often provides this service at the physical level) or 2) it has detected an access pattern. UFS allegedly thinks it has detected a pattern after seeing two consecutive pages accessed (some file systems wait for a third before starting to read ahead) – and may be so out-of-date that it will then begin reading ahead even if other disk requests are waiting to be served. The article also implies that UFS reads ahead in large increments (allegedly 1 MB in this case) rather than canceling a read-ahead request or asynchronously multi-buffering the data in small pieces (e.g., 64 KB at a time) such that if an explicit request arrives it can immediately terminate the read-ahead activity and service the request.
Still, when all is said and done any performance loss due to even UFS-style read-ahead is likely to be pretty marginal – especially in a random-access environment like InnoDB’s where this will usually happen only by coincidence. Of course, had the article enabled UFS buffering to put it on equal footing with ZFS’s buffering, we’d then have been better able to *see* whether UFS read-ahead might have been causing noticeable loss.
But in the end, all that is irrelevant to the underlying problem with the comparison. The best way to run InnoDB with UFS may well be to disable the UFS cache entirely – as long as the RAM thus freed up is then given to InnoDB’s cache to use (as was not done in the test). As seen by the graph, the best way to run InnoDB with ZFS, at least on the configuration used in this test, is *also* to dedicate most of the RAM to InnoDB rather than let ZFS handle it – and when this is done, the UFS environment out-performs the ZFS environment. We can get an idea from the graph of how much performance of InnoDB running on UFS would fall off in systems with less RAM available, but we can *not* get any idea of how much performance of InnoDB running on ZFS would fall off in systems with less RAM available (because all the ZFS data points on the graph used all the available RAM: they just varied how its use was split between InnoDB and ZFS) – in particular, there’s no reason to suspect that UFS would not out-perform ZFS on such systems, just as it does on the system tested.
– bill
Odd correlation you made here: “if mobile content developers and distributors are expecting PC-like storage performance and getting the N800 instead, consumers may not like it.”
The benchmark measures how long it takes to CREATE the file. While that is somewhat important, downloading media can be a background task.
What’s really important with media is playback performance. The MLC NAND Flash used in most handheld devices is notoriously slow at writes, but has remarkable read performance – usually 100-1000x better than write performance. It’s sufficient enough to playback video on an iPod, to be sure.