
Flash drives are known to have latency issues. The requirement to erase and program large blocks – even for small writes – means that if the drive runs out of free blocks a 50+ ms delay is possible while garbage collection works to provide one.
Since free blocks are used up in write intensive operations these slow downs occur when the system is busiest and rapid response critical – hence “write cliff.” Vendors understand the problem and take measures to reduce or eliminate the free block exhaustion problem.
Update: This is another in a series of posts on SSDs. The first, Are SSD-based arrays a bad idea? garnered some industry responses. The second, SSD arrays: limits of architectural critiques was a response to one of those from Howard Marks. I use the term SSD in a narrow sense to refer to flash drives packaged in standard SATA/SAS disk drive form factors rather than, for example, the flash DIMM design of the Sun F5100.
In theory, one would expect little difference between flash packaged as DIMMs or as disks. But this TPC-C data shows that the packaging makes a difference. End update.
So how’s that work in the real life?
Defining “real life” as audited TPC-C benchmarks simplifies things. While there’s wiggle room in the process – who would configure a real-world system with 4000 LUNS? – the basics are the same for everyone.
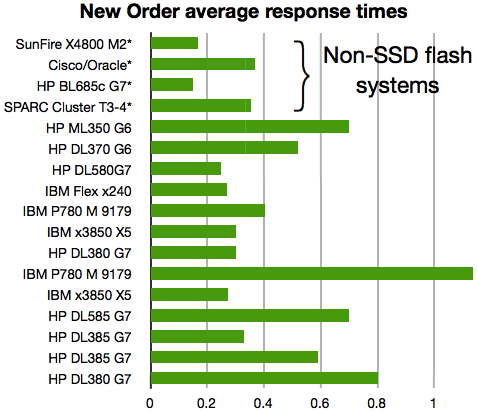
I took a look at the results from the last couple of years – all included SSDs except for the HP DL370 G6 (whose performance was competitive) – to see if any conclusions could be drawn about SSD performance. Focusing on the 2 most common transactions – New-Order and Payment – I graphed the results for the tested systems. The 2 non-SSD systems used either Sun’s F5100 or Violin Memory arrays.
The numbers measure how long it takes to complete a transaction that is typically made up of 10 or more I/Os. Thus small differences in I/O latency start adding up.
Results
In the graphs the systems that primarily use flash in non-SSD form factors are marked with an asterisk. The non-SSD flash storage comes from either Sun/Oracle or Violin Memory.
Let’s start with average response times.

Now let’s look at 90th percentile response times. I use different colors to alert readers to the fact that the scales are different: although all measurements are in seconds, the number of seconds varies on the X axis varies.


Now here are the maximum latency times. Note that some systems go out to more than 80 seconds.


The StorageMojo take
It appears that with glaring exception of the SPARC Cluster, the 3 systems with the lowest latency at the average, 90th percentile and maximum response times do not use SSDs. Some SSD-based systems equal or exceed the non-SSD systems at some points, but overall the non-SSD systems seem to have an important latency advantage.
What about the SPARC Cluster? Since the SPARC Cluster uses the same storage as the much lower latency SunFire, it is likely the issue is with the cluster, not the storage. Perhaps someone can run DTrace and figure it out.
What does this mean? While correlation does not prove causation, the results suggest that the behavior we expect from SSDs – the write cliff – is seen in real life. If so, it means that the current measures taken by vendors aren’t solving the problem.
Of course, if we didn’t have non-SSD flash storage there wouldn’t be a “problem.” We’d just be comparing performance, thankful that we had an option to disk arrays. But since we are going to flash, shouldn’t we have the fastest flash?
But I’m open to hearing other views on these observed differences. What else could explain these results?
Courteous comments welcome, of course. I’ve been doing some work for Violin Memory.

Isn’t Trim the answer to this? Or do you mean when the ssd is maxed out it suddenly performs much worse? Then it should be a firmware update that limits performance to just before that cliff.
F5100 *is* SSD based array
I updated the post to reiterate the distinction I make between SSD and DIMM-style flash. The F5100 uses a flash DIMM.
Robin, Anon above is correct, the F5100 ‘Flash DIMM’ modules are (in reality) a SATA SSD without the sheet metal wrapper.
See the photo here:
http://storagemojo.com/2009/09/01/the-sun-4-tb-flash-array-f5100/
That Marvell chip is a garden variety SATA controller same as used on commodity class SATA HDDs. Not that Sun or Oracle have ever tried to conceal this, even the product description is “P/N #371-4531; CRU,ASSY,24GB SATA FMODâ€
Likewise, the F5100 is an array of SATA SSDs.
So…what remains is, how to explain the differences in latencies observed in Robin’s analysis.
In transaction processing, response times of transactions depend primarily on the speed of the Redo/transaction log. The critical part of this workload is large-block, sequential writes (e.g., where Flash is weakest). Looking at the Sunfire x4800 M2 result (Full Disclosure Report pg 21) we see that the secret to low latency success is that the redo log was constructed of spinning rust behind a VERY fast caching RAID controller, as follows:
“Each REDO COMSTAR is configured with 11 2TB SATA (or SAS) disks through the 6Gb/s Internal RAID adapter…10 2TB disks are configured as a 10-way striped Logical disk using the internal LSI HBA RAID controller. The (DRAM) write cache on the controller is enabled…â€
http://c970058.r58.cf2.rackcdn.com/fdr/tpcc/Oracle_X4800-M2_TPCC_OL-UEK-FDR_032612.pdf
The silicon magic here has nothing to do with Flash, or whether it’s an SSD or non-SSD Flash. Rather the magic is the blazingly fast LSI SAS2208 RAID chipset coupled with it’s DRAM write cache and the stellar performance of good old fashioned magnetic disk, when kept “streaming†in a wide stripe set.
To get a sense for how slow the Sun Flash ‘SSD-on-a-DIMM’ modules are for write-inclusive work, one only needs to look at the SPC-1 result. With response times for writes in the 4-6 millisecond range, the numbers look more like HDD than SSD. And that, even considering they ‘short stroked’ the Flash to 50% of usable capacity!!!
http://www.storageperformance.org/benchmark_results_files/SPC-1C/Oracle/C00011_Sun_F20/c00011_Oracle_Sun-F20_SPC1C_executive-summary.pdf
A good Blog..
Check out Calsoft’s expertise in Storage services.
http://www.calsoftinc.com/storage.aspx
Ok…taking a look now at the HP/Violin Flash based result, this looks overall to be the fastest of all. If Violin’s “VIMM” (Violin Intelligent Memory Module) is really faster than SSDs, and is not subject to the Write Cliff, then surely HP would use this for the all-important Redo Log, yes?
Nope.
HP, with Violin’s “VIMMs”, was able to one-up the performance of Oracle with F5100 “DIMMs”, not by virtue of Flash, but rather by doubling the number of spinning disks over which the log file was striped. Twenty streaming spinners dedicated to the redo log, ten more than Oracle used, is the magic here.
Finally, why is the all-disk-and-no-flash HP DL360 result was so fast? In terms of maximum response times, when these systems are under the heaviest loads, this lonely ‘dinosaur’ HDD-only system was much, much faster than all but a couple of the SSD systems. How?
By now you’ve guessed. The HP DL360 all-HDD system dedicated 24 spinning disks in a RAID-10 stripe set as the log device. As a result it delivered maximum response times that were not only competitive, but flat out BLEW AWAY most of the Flash systems.
The higher latencies of the HDDs doing asynchronous I/O in the background are completely masked by the fast log device. Excellent, intelligent design on HP’s part, and food for thought for the rest of us.
HP, with Violin’s “VIMMsâ€, was able to one-up the performance of Oracle with F5100 “DIMMsâ€, not by virtue of Flash, but rather by doubling the number of spinning disks over which the log file was striped. Twenty streaming spinners dedicated to the redo log, ten more than Oracle used, is the magic here.
Saying somehow HDD is the magic behind Violin’s performance is like saying CD’s are the magic behind your iPod! Wow!
Really Spinning disks? Not sure if you are looking at the same data. There is no spinning disks or SSD with a Violin deployment. This is why it outperforms ExaData 2/3 with 5100 technology or even 3Par with even slower SSD technology.
KDMann: “surely HP would use this for the all-important Redo Log, yes?”
In what way does the location of the redo logs signify the viability of the storage? People in the storage world always make this mistake. Database redo logs cause large, sequential writes – perfect for disk. Flash is exceptionally fast at random I/O, which of course is where disk really fails. If you look at the latest TPC-C benchmark full disclosure reports you will almost always find primary data on flash and redo on disk.
Using the location of the redo as the basis of an argument is pointless and irrelevant.