
Google released a fascinating research paper titled Failure Trends in a Large Disk Drive Population (pdf) at this years File and Storage Technologies (FAST ’07) conference. Google collected data on a population of 100,000 disk drives, analyzed it, and wrote it up for our delectation.
In yet another twist of consumer-driven IT, the disks Google studied, PATA and SATA drives, are the same drives you and I would buy for personal use. As an ironic result, we now have better data on drive failures for cheap drives than the enterprise does for its much costlier FC and SCSI “enterprise” disks with their much higher MTBFs.
Google found surprising results in five areas:
- The validity of manufacturer’s MTBF specs
- The usefulness of SMART statistics
- Workload and drive life
- Age and drive failure
- Temperature and drive failure
I’ll give you the skinny on each after a note about MTBF and AFR.
Vendor MTBF and Google AFR
Mean Time Between Failure (MTBF) is a statistical measure. When the vendor specs a 300,000 MTBF – common for consumer PATA and SATA drives – what they are saying is that for a large population of drives half the drives will fail in the first 300,000 hours of operation. MTBF, therefore, says nothing about how long any particular drive will last.
Ideally, if you had 600,000 drives with 300,000 hour MTBFs, you’d expect to see one drive failure per hour. In a year you’d expect to see 8,760 (the number of hours in a year) drive failures or a 2.88% Annual Failure Rate (AFR). Is that what Google found? Nope.

There’s some discussion of this result in the Age and Drive Failure section, so be sure to keep reading.
Manufacturer’s MTBF specs
The vendors tell us what the MTBF rate is, so what else do we need to know? Quite a bit. Vendors define failure differently than you and I do. And, oddly enough, their definition makes drives look more reliable than what you and I see.
Vendors typically look at two types of data. First are the results of accelerated life testing, which are good at identifying the effect of some environmental factors on drive life, but don’t do a good job of reflecting real world usage. Second, vendors look at their returned unit data. Vendors typically report “no trouble found” with 20-30% of all returned drives, but as the Googlers note:
Since failures are sometimes the result of a combination of components (i.e., a particular drive with a particular controller or cable, etc), . . . a good number of drives . . . could be still considered operational in a different test harness. We have observed . . . situations where a drive tester consistently “green lights” a unit that invariably fails in the field.
Bottom line: MTBF figures are just like any other storage performance statistic: it’s a miracle if you see them in real life.
How smart is SMART?
Not very, as Google found, and many in the industry already knew. SMART (Self-Monitoring, Analysis, and Reporting Technology) captures drive error data to predict failure far enough in advance so you can back up. Yet SMART focuses on mechanical failures, while a good deal of a disk drive is electronic, so SMART misses many sudden drive failure modes, like power component failure. The Google team found that 36% of the failed drives did not exhibit a single SMART-monitored failure. They concluded that SMART data is almost useless for predicting the failure of a single drive.
So while your disk drive might crash without warning at any time, they did find that there are four SMART parameters where errors are strongly correlated with drive failure:
- scan errors
- reallocation count
- offline reallocation
- probational count
For example, after the first scan error, they found a drive was 39 times more likely to fail in the next 60 days than normal drives. The other three correlations are less striking, but still significant.
The bottom line: SMART can warn you about some problems, but miss others, so you can’t rely on it. So don’t. Back up regularly, and if you do get one of these errors, get a new drive.
Over work = early death?
A teenager might want you to believe that, but the Googlers found little correlation between disk workload and failure rates. Since most of us, including enterprise IT folks, have no idea how much “work” our drives do, utilization is a slippery concept. The authors defined it in terms of weekly average of read/write bandwidth per drive and adjusted for the fact that newer drives have more bandwidth than older drives.
After the first year, the AFR of high utilization drives is at most moderately higher than that of low utilization drives. The three-year group in fact appears to have the opposite of the expected behavior, with low utilization drives having slightly higher failure rates than high ulization ones.
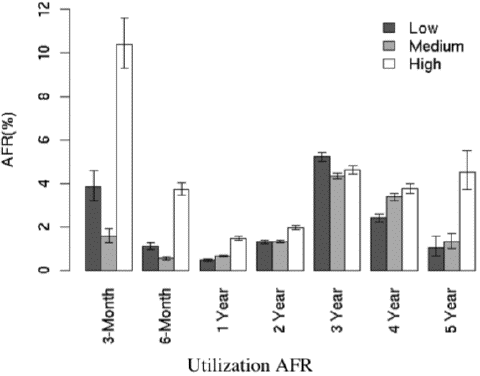
As the graph shows, infant mortality is much higher among high utilization drives. So shake that new drive out while it is still under warranty. And don’t worry about doing those daily backups to disk and other I/O intensive work.
Age and drive failure
This is the most irritating part of the paper, because the team admits they have the goods on who makes good drives and who doesn’t, but clam up due to ” . . . the proprietary nature of these data.” Hey, Larry, Sergey, isn’t Google’s mission to “. . . organize the world’s information and make it universally accessible and useful”? How about right here?
Google buys large quantities of a certain drive model, but only for a few months, until the next good deal comes along. As they say:
Consequently, these data are not directly useful in understanding the effects of disk age on failure rates (the exception being the first three data points, which are dominated by a relatively stable mix of disk drive models). The graph is nevertheless a good way to provide a baseline characterization of failures across our population.
The AFRs are neither as smooth nor as low as vendor MTBF numbers would have you believe.
Sudden heat death?
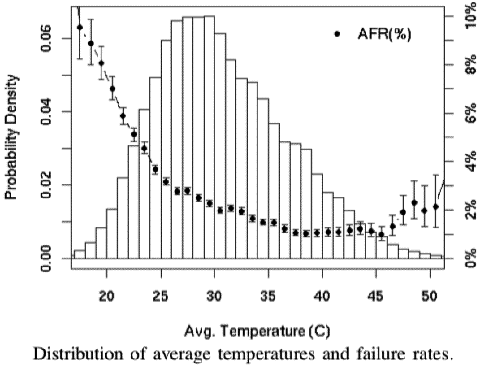
One of the most intriguing findings is the relationship between drive temperature and drive mortality. The Google team took temperature readings from SMART records every few minutes for the nine-month period. As the figure here shows, failure rates do not increase when the average temperature increases. At very high temperatures there is a negative effect, but even that is slight. Here’s the graph from the paper:
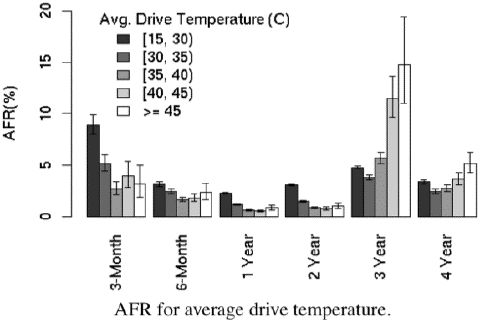
Drive age has an effect, but again, only at very high temperatures. Here’s that graph:
The Googlers conclude:
In the lower and middle temperature ranges, higher temperatures are not associated with higher failure rates. This is a fairly surprising result, which could indicate that data center or server designers have more freedom than previously thought when setting operating temperatures for equipment that contains disk drives.
Good news for internet data center managers.
The StorageMojo take
There is a lot here and the implications may surprise.
- Disk MTBF numbers significantly understate failure rates. If you plan on AFRs that are 50% higher than MTBFs suggest, you’ll be better prepared.
- For us SOHO users, consider replacing 3 year old disks, or at least get serious about back up.
- Enterprise disk purchasers should demand real data to back up the claimed MTBFs – typically 1 million hours plus – for those costly and now much less studied drives.
- SMART will alert you to some issues, but not most, so the industry should get cracking and come up with something more useful.
- Workload numbers call into question the utility of architectures, like MAID, that rely on turning off disks to extend life. The Googlers didn’t study that application, but if I were marketing MAID I’d get ready for some hard questions.
- Folks who plan and sell cooling should also get ready for tough questions. Maybe cooler isn’t always better. But it sure is a lot more expensive.
- This validates the use of “consumer” drives in data centers because for the first time we have a large-scale population study that we’ve never seen for enterprise drives.
On that last, the smart folks at CMU did a study that sheds light on that very point. Look for coverage of that paper here in StorageMojo RSN.
Update: Alert reader Julian points out in his comment below that I assumed the Mean TBF is equal to the Median TBF in my calculation of the AFR, and that I got the arithmetic wrong. He is absolutely correct. The mean tells us nothing about the distribution of failures: half the drives could fail on day 1 and the other half could last 10 years and we’d still have the same MTBF. With the “ideally” qualifier, I was attempting to suggest that if failures were evenly distributed over time, there would be one failure per hour. But that is a big “if” and as the Google data show, not how disks fail in the real world. Also, I fixed my arithmetic, so the vendors look even worse.
Update 2: Almost 4 years to the day after I posted this an alert reader pointed out a mistake in the AFR calculation above. Here’s the correct formula, courtesy the fine folks at Seagate. Take the MTBF in hours and AFR =1-(EXP(-8760/MTBF)). I corrected the post. End update.
Google curious???
How do those bad boys build the world’s largest data center? Check out Google File System, Google’s BigTable Storage System, Architecting the Internet Data Center and Google vs Amazon: A Choice Not An Echo. There’s more, so don’t be afraid to rummage around.
Update: NetApp has responded. I’m hoping other vendors will as well.
Comments welcome, as always. Moderation turned on to limit spam. You’ll just have to find your free ringtones somewhere else. Sorry.

Maybe I missed something, but I don’t understand why in the first graph “annualized failure rates broken down by age groups” drives >= 2 years have AFR of ~8%, but in later graphs, when drives >= 2 years are further characterized by utilization or average temperature, none of the utilization or temperature groups have as high AFRs as their composite. Are these graphs showing the same set of drives?
Temperature vs. failure correlation in server farm HDD’s, which run 24/7/365, has little relevance for home and office users.
Thermal *cycling* does. A typical home user will start/shutdown many 100’s of times a year, and an HDD which has to work from ambient temperature and which then gradually warms up until hitting much higher temps (which might be 50° C or more in a comfortably warm room if the HDD has no cooling at all) will very likely fail earlier than one kept down in the low-30° C range with fan cooling.
A little clarification – I’m suggesting that HDD’s which are regularly started/stopped should be kept within a reasonable distance of ambient temperature. The 2 in my PC typically idle at about 10° above room temp, and that may rise another 5-odd° working hard, (highest recorded temps are 32 and 33°).
That’s within reason, of course. If for some reason my heating failed and I was sitting in 5° C I wouldn’t want the drives working at 15-20°!
An outboard USB HDD I use regularly hit 50+ °, fully 30° above ambient, so I took the sled (which now doubles as caddy, in effect) out of the plastic case, and on a hot day it might now hit 37° , which I’m much happier with (it’s a backup drive and tends to be worked hard every time it’s powered up).
We might have an insight about the temperature vs. AFR graph.
Doing custom workstations and systems, new stuff is tested to see if it’s suitable or not, and we also get to play with the hardware we’ve replaced.
On hard drives we found this: cheap brands'(i’m not allowed to name them, but..well..it’s easy) models consistently reported unrealistic SMART temperatures, from 0 to -15°K(..!) relative to ambient temperature.
Since Google admittedly uses the cheapest drives it can buy, if they’re using the couple of brands we’re thinking of, this SMART temperature delta could explain the unexpected shift of the graph they obtained.
Regards,
Nicola
owner and CTO
Nice post