
Last year’s Google and CMU papers on disk failure rates (see Everything you know about disks is wrong and Google’s Disk Failure Experience) made the points that a) annual disk failure rates are significantly higher than manufacturers admit and b) that enterprise drives aren’t more reliable than consumer drives.
But in An Analysis of Latent Sector Errors in Disk Drives Lakshmi N. Bairavasundaram, Garth R. Goodson, Shankar Pasupathy and Jiri Schindler analyzed the error logs on over 50,000 arrays covering 1.53 million enterprise and consumer drives disks. It looks like the largest such study ever published.
Lakshmi was with the U of Wisconsin-Madison while the latter 3 work at NetApp. They published at the Sigmetrics ’07 conference last June.
A different kind of latency
Unreported or latent disk errors are real. That’s why vendors have stopped recommending RAID 5 on SATA drives.
Disks have a lot of errors, most of them transient. This study focused on Latent Sector Errors (LSE), defined as:
. . . when a particular disk sector cannot be read or written, or when there is an uncorrectable ECC error. Any data previously stored in the sector is lost.
They don’t say so explicitly, but these are surely NetApp arrays. They also comment on the effectiveness of media and disk scrubbing, a feature of high-end arrays.
Results
- Yes, there are “bad” disks: 0.2% of the drives had more than 1000 errors.
- 3.45% of the entire population had LSE over the 32 month study period.
- 8.5% of the consumer disks had LSE
- 1.9% of the enterprise disks had LSE
- In their first 12 months 3.15% of consumer and 1.46% develop at least one LSE
Causation
The team found several factors that contribute to LSE.
- Size matters. As disk size increases, so does the fraction of disks with LSE.
- Age matters. LSE rates climbed with age. 20% of some – but not all – consumer disks had LSE after 24 months. Rates climbed faster for consumer drives than for enterprise drives.
- Vendor matters. They also found that some vendors had much higher LSE than others. Due to the industry omerta they don’t rat out the offenders.
- Errors matter. A drive that develops one error is much more likely to develop a second. The second error is likely to be close to the first error. Once a drive develops an error, both enterprise and consumer drives are equally likely to develop a 2nd error.
Annual sector error rates
This figure from the paper indicates the variability in age-related error rates
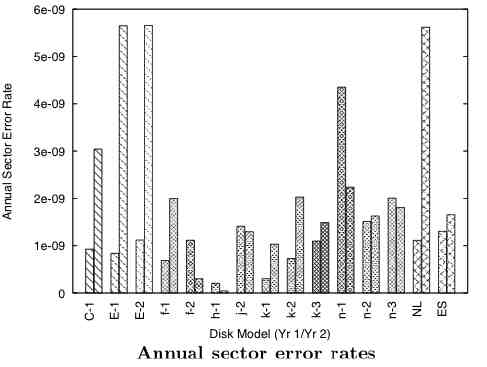
The caption states:
For each disk model that has been in the ï¬eld for at least two years, the ï¬rst bar represents Year 1 and the second represents Year 2. The NL and ES bars represent weighted averages for nearline and enterprise class drives respectively.
Consumer/SOHO users with large, cheap, old disks will see LSE. Another reason Desktop RAID is a bad idea. Not many consumers replace their drives every 24 months.
File system implications
File systems rely on disk-based data structures to keep track of your stuff. One of the key findings of the team is that disk errors tend to congregate near each other, like congressmen and lobbyists.
Therefore, file systems that replicate critical data across the disk are much less likely to lose your data than those, like ReiserFS, place critical structures in one contiguous area. Related issue: since disks virtualize the block structure, how do FS designers know where their data structures actually go on disk?
Media and data scrubbing
What’s the difference?
Media scrubs use a SCSI Verify command to validate a disk sector’s integrity. This command performs an ECC check of the sector’s content from within the disk without transferring data to the storage layer. On failure, the command returns a latent sector error.
While
A data scrub is primarily used to detect data corruption. This scrub issues read operations for each disk sector, computes a checksum over its data, compares the checksum to the on-disk 8-byte checksum, and reconstructs the sector from other disks in the RAID group if the checksum comparison fails. Latent sector errors discovered by data scrubs appear as read errors.
In the analyzed drives over 60% of LSE were found by scrubbing. Scrubbing is a high-end feature that works.
The StorageMojo take
The consistency of LSE as disk capacity increased suggests that there is a constant head/media issue. Since consumer drives are larger than enterprise drives, part of the higher LSE rate is explicable.
The higher LSE rate increase for aging consumer drives suggests that enterprise drives are higher quality. Or maybe their error correction is better.
Finally, drive vendors need to re-think their ECC strategies. As capacities increase so will LSE. Higher quality ECC comes at the cost of capacity. It is time to start paying that price.
Comments welcome, of course. Download the article pdf here.

This paper sounds like a big ad for ZFS/Btrfs. 🙂 But maybe that’s just my bias talking.
Speaking of ECC, I read that the codes are more efficient for larger sector sizes, so future disks with 4KB sectors may be more reliable. (Or vendors may cheap out and use less ECC to achieve the same level of (un)reliability they have now.)
Wes,
ZFS!?! Coming from NetApp – well, somehow I don’t think so!
For decades Detroit was convinced that quality didn’t sell, so they ignored it. One of the key trends in the consumerization of IT is that as we all become more dependent on our systems quality becomes more important. I think drive vendors could get a nice premium on LER – low error rate – drives, if they positioned them correctly.
Robin
A Netapp sponsored study that seems to indicate that Netapp’s disk scrubbing and hand-picked ‘enterprise’ drives really are worth 100x more than the cost of consumer/commodity drives and storage systems. Somehow I am not surprised.
So if 60% of errors were found by scrubbing, does that mean that 40% of errors returned wrong data without the drive reporting it?
Why no RAID 5 on SATA? What is recommended instead?
Joe, I agree that vendor-sponsored research is always suspect. But whether the extra features are “worth” the cost is something that each buyer needs to decide for themselves based on their application and business requirements.
Daniel, the errors that weren’t found by scrubbing were found by either failed reads or writes in roughly 50-50 proportion. The issue of “wrong data” is quite another kettle of fish.
Nathan, after a RAID 5 disk failure, your chances of seeing an unrecoverable read error on the remaining SATA drives is high. When your RAID controller encounters one it has to say it can’t recover the data, so now it is time to recover from a backup, meaning all the RAID recovery time was wasted. See Why RAID 5 stops working in 2009 on my ZDnet blog.
Robin
Looking at disk errors without also examining drive firmware versions misses the point. My experience in seeing thousands of arrays is that the vast majority of failures happen with specific firmware versions. The symptom is that the array stops reading and writing data at random times. An average is not the right measure if most of the errors fall into specific groups that are not measured. Another fact to consider is that if you buy multiple drives of the same size at the same time, chances are good that they will have the same firmware.
Thanks–Allen
Robin: The unrecoverable read error just affects a single sector, right? I realize this means you have file-corruption, which is clearly not good, but it doesn’t mean that all the RAID recovery time is wasted–you just have to recover a single file from backup. Unless I’m missing something? (I have a RAID-5 running at home, so I’m personally very interested in whether I should switch over to RAID-6 or just give up altogether and use backups).
Also:
> ZFS!?! Coming from NetApp – well, somehow I don’t think so!
It *is* kind of an ad for ZFS, though, as Wes said; NetApp alleges that ZFS stole from WAFL, and it’s an ad for WAFL, so by the transitive property… 🙂
Nathan, if a RAID system knew about files it would be a file system. Some cheapo RAID controllers will report an error and keep recovering, but then you have to figure out what is missing. The honest thing is for the controller to do is to stop. It doesn’t know if it has a database or a Paris Hilton video. Better to assume the former.
Transitive property! I like that.
Allen, on ZDnet someone advocated buying drives from different vendors to put in a RAID array to avoid that very problem. My concern is that then you are looking at problems from untested corner cases of controller/drive interaction x 6 or whatever.
I agree that the level of data disclosure in the paper wasn’t as deep as I would like. How about a follow on that goes out to 44 months? And gives mean, median and std dev? Maybe NetApp will surprise us at FAST next week.
Robin
Robin:
Hm, interesting, I was unaware of that. Knowing this, your article you linked earlier makes a lot more sense. For my case, I’d rather the RAID controller continue with the rebuild–I’d rather get random corruption on one sector than not be able to recover *any* of my data. But I see your point.
Sounds to me then like a home RAID like I have set up just serves to give a false sense of security. That’s too bad, because it’s really easy to just keep all my important stuff on the fileserver and assume my data are safe.
Thanks for the info.
Nathan
Nathan is right on the money about the transitive marketing. In my low-end storage worldview, NetApp doesn’t even exist. So when someone tells me to checksum my data, naturally I would reach for ZFS.
Robin,
Another interesting article;
BER as influenced by ‘latent’ sector failures is one of the key aspects in understanding the Mean Time to Data Loss (MTTDL) for disk arrays, once the weighting factors for disk BER, End User failure rate versus manufacturer, failure correlation (which is alluded to in the articles you link) and Batch Diversity are included the apparent ‘reliability’ of many large disk arrays is substantially lower than claimed. A simple rule of thumb is that a RAID 6(0) array built up out of sensible size RAID 6 groups (<20) is likely to achieve a MTTDL slightly less (/10) than the unadjusted RAID 5 MTBF based on hardware failures only. This is good news for people who have thrown out their big iron and are using smart file systems that actually talk to the disk in place of a volume manager that obscures disk events, also those file systems that use file level CRC. Once key differentiator is some file systems also read the parity stripe whenever they read the data which improves the error detection rate. There have been many posts by new ZFS users expressing their horror at the data error rate this class of file system exposes on their exising hardware, previously we probably blamed the data errors that were exposed on the application instead of the real culprit.
Latent sector failure is not a new issue, Hannu H Kari published a paper covering this issue in 1997, "Latent Sector Faults and Reliability of Disk Arrays" where the benefits of scrub technologies were well explored, the data from the paper referenced in this article seems to support his findings.
The claimed 'reliability' of large disk arrays is largely an illusion, once you understand that the calculated MTBF from most vendors does not include this type of data loss failure, it only considers simple hardware failure (not maintainability issues created by unecessary complexity and the loss of fault containment with an uber SAN) and takes no account of the huge performance degradation that many arrays suffer during parity rebuild (think those whose performance tanks when a snapshot is open) the achieved performance availability of many systems is several orders of magnitude lower than claimed, driving yet more expenditure on expensive, power consuming kit to maintain performance.
In terms of mitigating the impacts of the latent sector failure component of BER as described here smart background scan algorithms are undoubtedly effective but a cheap alternative for those running arrays with cheaper controllers or file system / volume managers that do not include this functionality is to simply back up the entire binary volume to dev null. Perversely a weekly backup to dev null, through forcing a complete surface read, can substantially improve the achieved data reliability by forcing the disks to detect sectors that took multiple read attempts and remap them elsewhere on the disk before the data is unreadable.
The final issue here is that latent sector failures raise another serious question about the viability of MAID disk arrays. As the data on the disks slowly degrades on the platters and this is kept in check by reading the disks to detect the re-reads as the data decays this does not bode well for a disk array that is designed to spend as much of its time as possible asleep. As many of the MAID platforms contain very large disks, which even at their maximum transfer rate in linear read can take many hours or even days to read the entire surface the weekly or so background scans could well use up much of the 'Idle' time of the MAID array simply preserving the data. This suggests that in place of MAID technology a non volatile media could be a far better option. Of course, smart file systems such as ZFS and the NetApp equivalent that only have to manage the actual data area have a significant advantage here over dumb volume managers and hardware controllers.
It screams ZFS to me too. That a read or write would fail would seem right up the alley of ZFS’s checksum error handling. An example of ZFS handling what sounds like the same thing this report describes: http://blogs.sun.com/elowe/entry/zfs_saves_the_day_ta
“Yes, there are “bad†disks: 0.2% of the drives had more than 1000 errors.”
You seem to have skimmed the paper a bit too quickly: 0.2% *of the 3.45% of the disks that had errors* had more than 1000 errors (i.e., about one drive in 14,000).
“file systems that replicate critical data across the disk are much less likely to lose your data than those, like ReiserFS, place critical structures in one contiguous area”
Hogwash: you’re almost exactly as likely to lose data with one as with the other, because the chances that an LSE (or even a bunch of adjacent LSEs) will affect more than data in a single user file is minute.
The most you could say is that you’re far less likely to lose *all* your data due to LSEs when critical metadata is replicated across the disk, but since the likelihood that LSEs will just happen to hit such critical metadata is already infinitesimal further reducing it (even by orders of magnitude) doesn’t count for much (investing in a meteor shield might make about as much sense).
And if you introduce any disk-level redundancy (mirrored or parity) into your system the likelihood that you’ll lose more than data in a single file due to LSEs (even if you don’t scrub at all) becomes pretty much indistinguishable from zero.
The reason that file system designers sometimes distribute multiple copies of critical metadata across a single disk is because it doesn’t cost much (in terms of space or performance) to do and helps give users a warm, fuzzy feeling, not because it’s likely to impact availability in any significant way with respect to LSE problems (though it can help with more drastic events such as head crashes that create a far wider path of devastation while still leaving portions of the disk accessible).
“In the analyzed drives over 60% of LSE were found by scrubbing.”
Another instance of too quick a skim, I suspect: while this casual observation does occur in section 6.2, the more detailed presentation in section 5.5 states that 61.5% of the LSEs in *enterprise* drives were discovered by scrubbing while 86.6% of the LSEs in *nearline* disks were discovered by scrubbing, for an overall average of 77.4%.
“Scrubbing is a high-end feature that works.”
Perhaps a great deal better than you realize, even after taking the above corrections into account: apparently the only reason that scrubbing did not detect 100% of the LSEs was because user read and write operations discovered them before the scrub had a chance to, though it would have been nice to see it stated explicitly that no unrecoverable sectors (at least within the 0.1% rounding error) occurred during reconstruction after a disk failure during the test period.
“I think drive vendors could get a nice premium on LER – low error rate – drives, if they positioned them correctly.”
That suggestion is just as silly as it was when I responded to it 7 months ago in http://storagemojo.com/2007/07/19/why-arent-disk-reads-more-reliable/ – where I didn’t even mention the fact that demanding a *premium* for such drives would make them even less competitive (compared with using conventional drives in larger numbers to attain at least comparable reliability with potentially better performance in the bargain).
Hell, it’s going to be tough enough preserving a marketable distinction between ‘nearline’ and ‘enterprise’ drives (at least with anything like their current price difference: SATA drives can usually clobber enterprise drives already on price for a given level of aggregate performance in most enrivonments), without attempting to introduce an *additional* new tier.
“after a RAID 5 disk failure, your chances of seeing an unrecoverable read error on the remaining SATA drives is high.”
Not if the RAID-group size is reasonable (say, no more than 9 drives – 5 or 6 would be more typical) and you scrub reasonably frequently.
More specifically, this paper found that 91.5% of the nearline (SATA) disks developed no LSEs at all over the 32-month test period. Of the remaining 8.5% that developed at least one LSE over the 32-month period, the fact that 3.15% developed at least one LSE within 12 months suggests that the rate of incidence of disks with at least one LSE (though not necessarily the total number of LSEs) was roughly linear in time, which would imply that in any two-week interval between complete scrubs (the frequency cited in the paper) there would be about a 0.12% chance that any given SATA drive would develop at least one LSE.
So if you had a 9-disk group and one failed, if you scrubbed every two weeks (and on average the failure occurred half-way through that period) there’d be about a 0.5% chance of encountering one or more LSEs (most disks that had any LSEs at all had only a very few) during reconstruction. With a more typical 5-disk array there’d be about a 0.25% chance.
While these probabilities are non-negligible, I wouldn’t call them ‘high’ – and in particular, for the typical (5-disk) RAID-5 array the likelihood of encountering *any* unrecoverable data due to LSEs during reconstruction is only 4x as high as it would be for an equivalent RAID-1/RAID-10 (and effectively only around 2.5x as high, considering that you’d need 60% more mirrored disks to achieve the same storage capacity and thus have something like a 60% higher probability of having a disk fail in the first place).
You’ve been clamoring about the dangers of RAID-5 long enough, Robin: start listening when people try to give you a clue. You’ve taken a legitimate problem (the fact that LSEs can interact with disk failures to cause data loss in RAID with non-negligible probability), ignored the major impact that scrubbing can have in reducing that problem (by over two orders of magnitude if you scrub every 2 weeks during a disk’s nominal 5-year service life – and that doesn’t take into account the impact that regular scrubbing has by causing the disk itself to revector failing but still readable sectors *before* they generate LSEs, which this paper alludes to but does not quantify), and ignored the fact that mirroring suffers from it not much less than typical parity RAIDs do.
“When your RAID controller encounters one it has to say it can’t recover the data, so now it is time to recover from a backup, meaning all the RAID recovery time was wasted.”
Only if your controller is brain-damaged: otherwise, it should report the problem, recover the rest of your data, and leave the unrecoverable (logical) sector marked ‘bad’ (probably waiting for a subsequent write to ‘revector’ it) – just as would happen with a single drive when it encounters an unreadable sector (it doesn’t just take all its marbles and go home if that happens, and neither should the array). The likelihood is *overwhelmingly* high that such a bad sector will occur in the data of some single file rather than cause wider damage by occurring in some critical metadata of more global significance.
Of course, as explained above if you scrub reasonably often the chances that your RAID will encounter *any LSEs at all* during reconstruction after a disk failure are quite small (well under 1%), and the chances that it will encounter any that would affect more than a single file are several (usually many) orders of magnitude smaller still.
“if a RAID system knew about files it would be a file system”
So would a disk – see my comment just above: why, exactly, do you think they should behave differently in this area?
“This paper sounds like a big ad for ZFS/Btrfs. 🙂 But maybe that’s just my bias talking.”
I suspect the latter: the only advantage that ZFS has in this area over a conventional (non-brain-damaged) RAID-plus-scrubbing approach is in its additional replication of metadata, and the chances that an LSE problem during reconstruction will hit critical metadata (rather than plain old user data) are infinitesimal.
– bill
as descibed above:
“A data scrub is primarily used to detect data corruption. This scrub issues read operations for each disk sector, computes a checksum over its data, compares the checksum to the on-disk 8-byte checksum, and reconstructs the sector from other disks in the RAID group if the checksum comparison fails. Latent sector errors discovered by data scrubs appear as read errors.”
what is the “on-disk 8-byte checksmu”?
Is it a signature of the sector contents ,which could reflect the small changes?
if that’s ture, is there any standard to choose such signature?
I’m a students in China, so sorry for my poor English.