
The Object of My Affection
Why do we manage blocks? That construct is getting old.
You might say we manage blocks because disks have blocks and we build storage out of disks. But what if disks didn’t have blocks? No more block management. We’d simply manage . . . . OK, what would we manage?
Enter the object
Bruce Lee could make an entrance. Objects, not so much.
Like files, objects contain data. But they lack several things that would make them files. They don’t have:
- Hierarchy. Not only are all objects created equal, they all remain at the same level. So you can’t put one object inside another.
- Names. At least, not human-type names like Pamela Anderson, Claudia Schiffer, 2006 Taxes or Brad Pitt.
- User access control. Objects just lie there like a dollar on the street, waiting to be picked up. Objects don’t know who they belong to.
The missing synch
A file system’s user-facing component provides those missing elements. You decide which files belong in which folders. You give the files names. You decide which users have access to which files and what those users can do with those files.
So objects all look alike. Some are bigger and some are smaller, but until we get them dressed and named, they aren’t files. Yet they are a lot closer to files than blocks are. Which means that if you choose to manage objects you no longer have to worry about blocks.
Is this going anywhere?
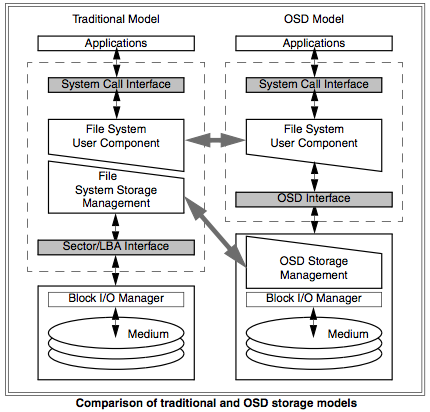
Patience, padawan. Object-based Storage Devices or OSD. OSD is a standards effort defining how storage devices, like disks, disk arrays or tape libraries could present a standard, SCSI-based, interface to serve objects to the user-facing file system component. This moves the processing required for figuring out which sectors contain a file’s data from the server to the storage device.
Here’s a diagram of the change from block-based to object-based storage:
The StorageMojo take
OSD is cool, if it ever comes to market. Moving processing off the main CPU frees up cycles for mission critical applications, like improving the frame rate in Quake.
Today’s disk drives have more computes, RAM and I/O bandwidth than $300,000 minicomputers did 25 years ago. Why let all that capability go to waste, especially as data volumes explode?
So the device will manage the objects and the server/workstation will manage the file user interface. We are still moving away from the model of the original disk drives where the CPU directly managed the head movement. OSD will help create more scalable and easily managed systems. This is another important step towards building the massive scale-out storage systems of tomorrow.
Comments welcome, as always. I think OSD is cool, but maybe you don’t. I’d like to know why.

RE: “We’d simply manage . . . . OK, what would we manage?”
Interesting thought…
Objects are pretty close to bytes and blocks but less than files. Not talking size here but atomic/molecular qualities.
My solution to this was to introduce the “Unit of Information”. I have a big, long “Operational” definition to try and cover all the exceptions, dead-ends and loop-holes. The “Unit of Information” has been greeted with deafening silence. The “Managed Unit of Information” hasn’t fared well either.
A “Managed Unit of Information” is a “Unit of Information” with an SLA (Service Level Agreement). This means some human decided the Unit of Information has ROI (Return on Investment) capability. All Units and Managed Units of Information have TCO. It is the ROI/TCO ratio that matters.
You can use the same approach for OSD and its objects. It fits nicely.
ECM (Enterprise Content Management) needs a Lower Metric molecular concept to deal with Information. The atomic is not sufficient. The atomic works fine for Units of Technology.
You can also apply qualities like scalar and vector to OSD objects or Units of Information. Vector Information has more ROI potential but higher TCO than scalar. Applying these qualities can be very interesting for mapping the Information Content.
When you have all these objects flying around in ad hoc Information space the “Speed Limit of the Information Universe” becomes very important.
How quickly can these objects be aggregated and dispersed in response to requests?
The Information Stack (IS) takes on a new meaning and significance.
Hmm, whilst I see the point, I don’t see how it could be easily adopted. Existing file systems, DBMSs etc have all been built and optimised to work with blocks. That would require rather a large rewrite of an awful lot of code. If there was a nice migration strategy, then perhaps it does have a future.
The OSD component keeps track of which blocks are used to store the object. In that decision it must also take care of performance issues: is this object accessed often? Is it mostly read or also written to? Such issues determine where on the disk (inner or outer track), striped over how many disks and even on what type of disk the object should be stored. To know these parameters requires metadata that today typically resides in a directory in the file system. That could be separated, but then each object has a sidecar to keep track of these usage parameters, not quite your naked object any more. Also, to be able to optimally allocate blocks to the object, the OSD function must reside way above the disk drive layer, so we probably need more than simply an extension of the SCSI protocol. Otherwise, certainly an interesting thought. Always good to create separate architecture layers for separate functions.
interesting…
What would be the key reason to move away from blocks to objects?
Indeed, as ernst pointed out, the term object looks strangely simplified to me. I do not know anything about OSD (yet another TLA with 20 meanings, including ObjectStorageDevice?, OnScreenDisplay, etc), but why would an object not have a name, access controls and metadata ? In software, it even has methods to access it, encapsulation etc.
On the other hand, it’s clear to me that the storage of the future won’t be a hierarchical file system. Directories are things of the past. Attaching resources to a tree is a pain, and there should never be something like two different copies of the same information just because it’s located in another leaf of the tree.
So, why not consider “Storage 2.0” directly, and introduce more meaning (and security) in the storage subsystems ? From what I see here, OSD is likely “too little too late” to change a whole industry.