
Part I discussed Amazon’s internal operations from the perspective provided by the paper Advanced Tools for Operators at Amazon.com (pdf). Amazon runs one of the world’s largest OLTP systems and they are beset by many of the same legacy system problems that enterprise IT faces. Their work re-architecting Amazon’s IT in situ to SOA is like rebuilding an SR-51 while on a reconnaissance mission over hostile territory. Except of course, Amazon has a ‘net.
Here in Part II I’ll discuss the actual tools that Amazon’s Mission Impossible team developed – and I’ll include more info about credit at the end of this note.
Amazon’s IT admin staff faces several critical problems:
- Dependencies and failure propagation
- Limited situation awareness
- Overwhelming detail
To address these issues, Amazon engineers built a tool they named Maya.
Maya, the tool
“In Advaita Vedanta philosophy, maya is the limited, purely physical and mental reality in which our everyday consciousness has become entangled.” Running multiple clusters with hundreds of servers in each qualifies as a consciousness-entangling process.
To help sort it out, Maya presents a GUI (see below) formally, a directed graph. The health of each component – web page, service, database – is shown by the color of its dot: black = healthy; red = hurting; and gray = we have no idea. By showing connections between components, admins can see, ideally, where failures begin and focus on the root problem.
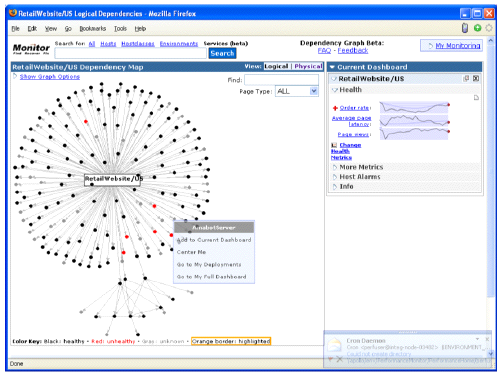 The Maya GUI
The Maya GUI
Wikiboards
What is even cooler though, is that each component (or dot) has its own associated dashboard that works like a Wiki: the problem resolvers can edit the dashboard to exclude what knowledge and experience tell them is irrelevant to understanding the health of the component. So as different developers cycle through the support role, their knowledge of relevant dependencies gets captured in the Wikiboard. The people closest to the problem define the important metrics and that knowledge persists in the Wikiboard.
Using social networking technology to augment datacenter operations seems pretty creative to me.
How well does Maya pierce the veil?
Maya has been available for Amazon employees since November 2005. Results are mixed so far, but the team has learned some valuable lessons.
- Users think Maya still displays too much information, so the team is looking at simplifying the display further
- Maya today offers only incomplete coverage since Amazon has multiple management frameworks, nor can all dependencies be detected automatically
- Everyone would love it if Maya were smart enough to suppress alarms for services that depend on another failed service
I hope Amazon will author another paper telling us what they learn.
Automating Intelligence Collection
Maya is focused on the big sev1 problems. Yet Amazon has lots of sev2 problems that effect only individual servers, due to the high rate of code churn. Documenting the issues and their fixes is almost impossible, so the paper looks at using another common web tool, clickstream tracking and analysis, to see if it could provide a useful substitute.
The idea is to capture the actions of experienced troubleshooters as they work problems, and, when a seemingly similar problem occurs, recommend those actions to the current, perhaps less experienced, troubleshooter as a possible solution.
Of course, as experienced Unix developers, the Amazon engineers don’t confine themselves to clicking on a GUI, but also use command-line interfaces (CLI). Gathering CLI actions is important for developing a complete solution as well.
In testing their prototype sev2 recommendation system, the team found that it successfully captured:
- almost 100% of the useful metrics – plus some less-useful ones
- and, more importantly, after two months 75% of the captured metrics were deemed useful by responders
Amazon captures millions of metrics on its servers. Yet the number of useful metrics for troubleshooting a problem is about 10. So the system does help to winnow the wheat from the chaff.
Where do we go from here?
To paraphrase Uncle Ben in Spiderman “with great infrastructures comes great problems”. And Amazon, handling billions of dollars of customer money, has much higher service level requirements than purveyors of free web services do. Add to that the organic nature, i.e. messy, of their system evolution and they have a problem set that is much closer to that of a large enterprise than most other internet data centers do.
Applying advanced design and web tools to the problems seems, as one would hope, very smart. I really like the Wikiboard idea – which reminds me of a tool we used for years in DEC, VAXnotes – because persistent storage of knowledge in an intuitive framework is what the internet is ideally all about. “Wisdom augmented drilldown” should become part of every management product.
Clickstream analysis seems very creative as well. While we want autonomic computing, automating the collection of human problem-solving skills makes a lot of sense as well. I suspect we’ll see similar ideas embodied in enterprise management in the near future.
Addendum/update to the original article
I received a nice note from a gentleman involved in the Amazon team who made an important point. It isn’t clear to me that naming him will help with his bosses, so I’m leaving his name off. I hope that’s ok.
Thankyou for your review of Peter’s paper studying our operations. One of a few corrections I would like to point out [regards the] opening paragraphs:
Maya was built solely by Amazon engineers with no input from the esteemed names you mention, but we whole-heartedly agree that they are quite smart. To be clear the really smart people who build these tools are not the ones you named above (it could be interpreted that way) and I would just like to see the credit applied appropriately. The Amazon engineers are that conceive of and deliver these tools are on line two of the credits: Ajit Banerjee, Ramesh Jagannathan, Tina Su, Shivaraj Tenginakai, Ben Turner, Jon Ingalls.
Peter Bodik joined as part of a PhD summer internship program that we have established with Berkeley and Stanford (checkout: ROC http://roc.cs.berkeley.edu/) which *I* feel is pretty good research. His visits with us focused on how operators use near real-time visibility tools as leverage when managing a service oriented architecture on a world wide scale.
I appreciate the update. As a trade-school graduate (MBA) I don’t have any concept of how authorship for academic papers gets handed out. It appears that Peter Bodik actually wrote the paper, with advice from the luminaries I likened to a Mission Impossible team, and including, as noted above, the work of the really smart Amazon engineers.
Now, a word of advice for Amazon marketing and HR: Google has done themselves a world of good in the tech community by allowing their folks to write papers about Google infrastructure. You should follow their lead because, IMHO, Amazon has an even better story to tell than Google. If you’d like to know why, my contact info is elsewhere on the site.

Amit,
It certainly wasn’t my intention to leave that impression with readers, nor do I think that is the case here.
My take on this is that the attribution is not an Amazon issue. In fact, the system that has developers on-call to fix problems seems designed to assure individual responsibility and accountability with a very personal reward: a good night’s sleep if your product works.
As I noted, the issue seems to be with how credit for academic papers gets handed out, which cuts both ways. Having Patterson’s name on a paper is certain to get more attention for the rest of the folks listed. If engineers went to cocktail parties, saying “In the paper I authored with Dave Patterson, Michael Jordan and Armando Fox we found . . . .” would get you a few status tokens pretty fast.
I certainly don’t fault Amazon. I’m not clear on why you do either.
Robin