
My colleague at Data Mobility Group, Walter Purvis, sent me a link to Mark Round’s site with new ZFS performance numbers.
Thanks to Storage Forum for the link that caught Walter’s eye.
Here’s some storage eye-candy
The performance comparison is between UFS and ZFS on Solaris. In this graph, the numbers snuggling down at the bottom are UFS.
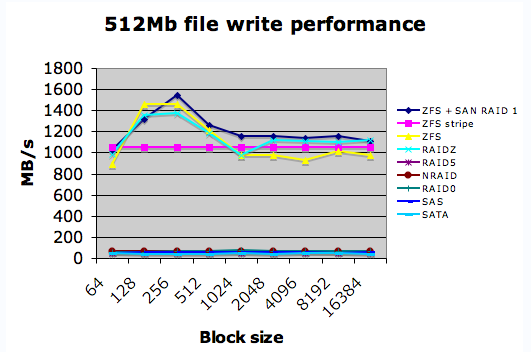
One of Mark’s interesting conclusions:
So what seems to be happening is that ZFS is caching extremely aggressively – way more than UFS, for instance. Given that most of the “I/O” was actually happening straight to and from the ARC cache, this explained the phenomenal transfer rates. Watching iostat again also showed that during the read tests, I was using far less of the SAN bandwidth. While performing “read” iozone tests on UFS, I was nearly maxing out the fabric bandwidth which could have lead to resource starvation issues, both for the host running the tests and for other hosts sharing the SAN. Using ZFS, the bandwidth dropped down to 50MB/s or so at peak, and much lower for the remainder of the tests – presumably due to the caching and prefetch behaviour of ZFS.
The StorageMojo take
Sun’s ZFS crew looks like they are delivering some goods. This kind of performance will be very welcome to Apple’s pro media users, assuming they get ZFS on OS X Server by October.
Update: Kevin Closson’s blog has a response to Digital Badger, saying, as near as I can make out, “Whisky Tango Foxtrot.” Nicely, of course.
Comments welcome, of course. I’m cranking on a project right now, but I will be getting to SNW RSN.

Most interesting, and points out the effect of a transactional, copy-on-write filesystem, especially with parity RAID volumes.
I like to say every ten to fifteen years there is a fundamental architectural change in filesystems. The last big shift, in the mid-1990s, was the emergence of extent-based filesystems, such as IBM JFS, Veritas VxFS, SGI XFS, and Microsoft NTFS, along with many others which followed.
with a small workload such as 512mb you are basically just stressing your memory. If your ufs is mounted forcedirectio this is still going to disk (real life for a database) while ZFS is doing this in memory (as ZFS still lacks a directio path). So these results actually mean nothing apart from the fact that memory performance beats disk-io. I did some tests in out production environment using 4g database tablespaces and the results for “random write” had a 10% advantage for ZFS (using Oracle as a database). However as ZFS forces you to use the systems memory as a cache it is next to useless in an oracle Environment.
Of course, this is just a personal opinion … 😉
El Burro – I don’t get it. You got 10% more performance but just because ‘… ZFS forces you to use the systems memory as a cache it is next to useless in an oracle Environment…’ . Why? What was your actual problem with ZFS+Oracle other than ZFS gives you more performance?
Please check Roch blog entry on directio & zfs – http://blogs.sun.com/roch/entry/zfs_and_directio
For other ZFS benchmarks see also http://milek.blogspot.com/2007/04/hw-raid-vs-zfs-software-raid-part-iii.html
i do not see the problems with some bloggers.. reading this it’s a straight forward story
“” So what seems to be happening is that ZFS is caching extremely aggressively – way more than UFS, for instance. Given that most of the “I/O” was actually happening straight to and from the ARC cache, this explained the phenomenal transfer rates. Watching iostat again also showed that during the read tests, I was using far less of the SAN bandwidth. While performing “read” iozone tests on UFS, I was nearly maxing out the fabric bandwidth which could have lead to resource starvation issues, both for the host running the tests and for other hosts sharing the SAN. Using ZFS, the bandwidth dropped down to 50MB/s or so at peak, and much lower for the remainder of the tests – presumably due to the caching and prefetch behaviour of ZFS.
The upshot of all this is that it seems ZFS is just as “safe” as UFS – any application that really wants to be sure data has been written and committed to stable storage can still issue a fsync(), otherwise writes to the disks still happen at around the same rate as UFS, it just gives control back to the application immediately and lets the ZFS IO scheduler worry about actually emptying the caches. Assuming I lost power half-way through these writes, the filesystem would still be guaranteed to be safe – but I may still lose data (data loss as opposed to data corruption, which ZFS is designed to protect against end-to-end). It can also give you a staggering performance advantage and conserve IO bandwidth, just so long as you’re careful you don’t get misled into believing that your storage is faster than it actually is and have enough memory to handle the caching!
Robert, if system memory is used for caching you will have database corruption if your host crashes. That’s why it is a “best practice” to run oracle only on filesystems that are mounted forcedirectio (actually in a “filesystem benchmark” this will yield bad results, but for oracles own IO optimization this is not a drawback). So if ZFS caches in system memory I will not run a productive database on it – an the comparison is useless. Actually, if you do an iozone with large files (beyond caching boundaries) and check random write performance (really stressing disk io) there is not much magic to ZFS compared to UFS. Of course, if your application does not have a consistency problem with being cached in memory you’re fine with ZFS. Actually as far as a I can tell, SUN is not really endorsing ZFS for Oracle at the current time – probably for reasons stated above.
El Burro, the recommendation about forcedirectio is not at all data integrity related. Oracle makes sure to fsync() all data which needs to be on disk (i.e. redologs after each commit or checkpoint). This will work even if you have a host filesystem cache.
The reason for the directio setting is to avoid unneeded double caching of the blocks, because oracle manages a cache itself, and data which is read from disk wont be read again from oracle (unless memeory is low, but it is lower if you have two caches).
However I do not know – but I asume – that ZFS has a working f(data)sync() implementation.
The nice graph at the top of this article seems somewhat impressive, but the difficulty is when one starts asking critical questions.
What was the physical network topology in this test? (Was there one, or was this test just done from a Solaris machine with some ZFS file-systems created?)
How much cache/system memory was available for ZFS to cache with?
It is handily noted that 512MB files were used, but how many?
It makes it quite difficult to know if caching boundaries are being surpassed without understanding in fact how many 512MB files were used and how much total cache was available on the system in question…
More than this…
What storage was unsed in this configuration? (Vendor, Model, etc.?) And is it safe to assume that this is going over a straight through Fibre Channel connection to the backend storage from the server/machine in question?
Thanks.