
Erasure coded (EC) storage has achieved remarkable gains over current RAID arrays in fault-tolerance and storage efficiency, but the knock against it is performance. Sure, it’s highly available and cheap, but it’s slo-o-w.
Advanced erasure codes – those beyond traditional RAID5 and RAID6 – require a lot more compute cycles to work their magic than the parity calculations RAID uses. With the slowdown in CPU performance gains, waiting for Moore’s Law to rescue us will take years.
But in a recent paper Joint Latency and Cost Optimization for Erasure-coded Data Center Storage researchers Yu Xiang and Tian Lan of George Washington University and Vaneet Aggarwal and Yih-Farn R. Chen of Bell Labs tackle the problem with promising results.
3 faces of storage
The paper focuses on understanding the tradeoffs through a joint optimization of erasure coding, chunk placement and scheduling policy.
They built a test bed using the Tahoe open-source, distributed filesystem based on the zfec erasure coding library. Twelve storage nodes were deployed as virtual machines in an OpenStack environment distributed across 3 states.
Taking a set of files, they encoded each file i into ki fixed-size chunks and then encode it using an (ni, ki) MDS erasure code. A subproblem is chunk placement across the infrastructure to provide maximum availability and minimum latency.
The researchers then modeled various probabalistic scheduling schemes and their impact on queue length and the upper bound of latency.
Joint latency – cost minimization
The 3 key control variables are erasure coding scheme; chunk placement and scheduling probabilities. However, optimizing these without considering cost is a ticket to irrelevance.
It’s not any easy problem, as the paper’s pages of math attest. But one graph shows what is possible with their JLCM algorithm:
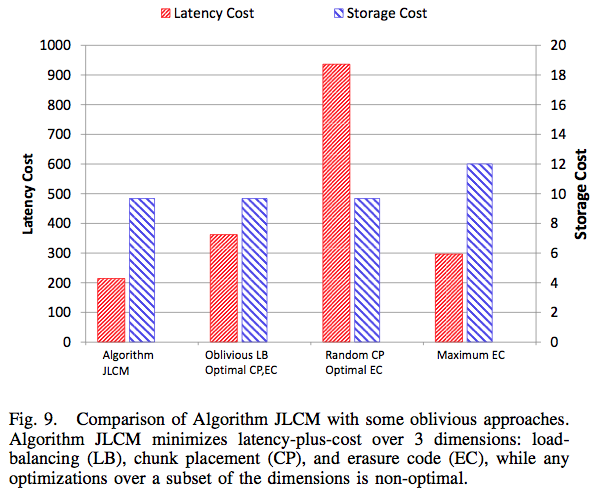
Graph courtesy of the authors.
The StorageMojo take
If CPUs were getting faster as they used to we could wait a few years for high-performance erasure-coded storage. But unless Intel puts optimized EC co-processors on its chips – similar to its GPUs – we’ll have to do something else.
EC storage faces a higher bar than earlier innovations. Even pathetic RAID controllers could out perform a single disk. Similarly, early flash controllers could as well, thanks to flash performance.
But EC storage is slower than even disk-based arrays. But the financial and availability benefits of cracking this particular nut are huge.
The paper offers a valuable perspective on moving EC storage forward. Let’s hope someone takes this opportunity and runs with it.
Courteous comments welcome, of course. What would it take to accelerate EC performance?

Well, not being funny, but TahoeFS is written in Python. So, I can see some room for gains, there!
As for general approaches to performance, this is a distributed FS, so I would at least investigate what can be done by implementing FS primitives and domain metadata in a processor on a NIC, and DMA’ing aross the bus to NVMe storage.
Nothing in a distributed system is going to be fast, not with erasure coding or any complex low level management, when first you need to establish a routed path to the file. I’d say the best we can hope for, is the PCIe bus comes to our aide, but this will present some interesting decisions for driver design and how drivers fit with the architecture. I think the problem set appeals to high level addressing, i.e. object storage approaches.
I hope soon(ish) to have our first NVMe systems to test, and the low latency with the option of standard drive packaging, is exciting. I’m disappointed there seems to be rather slow takeup for drive package support, e.g. the intriguing, and, depending on your POV, perplexing or even frustrating, Dell PE 730 approach of offering many 1.8″ sleds, to address, among other issues, RAID for latency. I’m in the perplexed to frustrated camp: prior to NVMe, I would have leapt at such a option. The choice is, by my view, a _ahem_ interesting option..
FWIW, a lot of the performance that is potential, I would very much like to use, and lose, in a trade for features that are spending time in labs, right now. If I took a company wide upgrade to the best storage that’s available now, i could lose a lot of performance without pain. Not every pool of storage is either a pool, nor needing absolute performance, and I see the future problem to be getting enough network bandwidth to the desktop, or workgroup, looking at the slow move to/from 10GbE. Distributed FSs are going to get a lot of fresh attention, at least I hope so.
and there I am, brought by commenter “sharklasers” to your ’09 “end of `1.8″ HDD drives” !
given the density, where might we be at with 1.8″ HDDs now? 1TB?
Consumers aren’t buying 3.5″. They are buying SSDs, in M or custom formats, or, maybe in the nearish future, as DIMMs. I see the DIMM flash approach as potential in consumer / enthusiast space. Look at the world of OEM Android devices. If you squint, you can imagine that what holds back many companies from competing, is the cost of custom design. But consumers clamor for smaller in every realm. Mini desktops ./ HTPC and there’s demand in the enterprise certainly for smaller form factor PCs, VESA mount e.g.. I imagine there might be a convergence for everything not fully custom, i.e. high end phones and tablets, to “mini” designs, where flash on DIMM could be a standard approach to mass storage.
Now, if only there were *cheap* 1.8″ HDDs at 1TB +, and I know what server I’d buy tomorrow, for a small office. The Dell 730 option I mentioned, puts 18 of them at the front. At present, it seems a dicey game, to go cheap, with SSDs. I am keeping in my pocket a veritable budget Nokia candy bar phone, which has worn down its memory so it cannot hold more than a few text messages, as a reminder… that and to deal with messages as they come in, for a bit of self discipline.. I am sure it will be flash wear that obsoletes the next phone I buy, and that this is a reason SD card support seems to be not present in some models. Absurdly, the top of line Lumia 930.. do they imagine customers for those will upgrade before memory wear affects them? Sandisk just launched a 512GB (no typo) SD card. I’m just getting over having lost my last phone, with a 64GB mini SD in it, which made me think a younger me most definitely would have fainted..
sorry for the aside. I have a genuine purpose: I’m worried about the potential for demise of HDD in the consumer space especially. Selling without a SSD is getting close to impossible. People want the shrink to fit formats for design. In the consumer space, SSD’s physical resilience is moot: almost no tablets can be repaired if physically injured. The answer all hail is the cloud. But distributed FSs are languishing in labs. Having a (vast by past needs) 15GB of OneDrive or whatever comes with what you are sold, is not a answer, alone. Hence we need software to deal with this. And, since we can afford to give away performance, in so many instances, maybe even something written in Python, may come to our aide.
This is your angle, Robin! How consumer space interacts with enterprise demand and vice versa. Any views, or articles forthcoming?
My reading of this paper is that the latency they address is due to queuing delay on the storage servers under contention and not the computation latency of the erasure code. Faster CPUs would certainly reduce the erasure coding latency but are not likely to help the storage contention queuing delay.
Gary, you are correct about the paper. They’ve attacked the problem that Cleversafe and other geo-distributed EC storage face.
I was implicitly looking at this from a local EC storage perspective, such as Amplidata – who also does geo-distributed – and the impact the research could have on them. Remove the network latencies, lay out the data better, process the math faster and higher performance should result. Should have made that explicit in the post.
Robin
There are always efficiencies that can be tuned in a distributed architecture, this technology is only in its infancy. We (Caringo) have chosen to “squeeze greater” performance by removing multicasts dependencies, distributed manifests and created global indexes. We have seen substantial performance increases in EC rebuilds as a result . Yes, at the end of the day Reed-Solomon will be CPU bound to a certain degree but that a that probably the least of your worries when build a better mouse trap!!!
Chad