
From their earliest days, people have reported that SSDs were not providing the performance they expected. As SSDs age, for instance, they get slower. But how much slower? And why?
A common use of SSDs is for servers hosting virtual machines. The aggregated VMs create the I/O blender effect, which SSDs handle a lot better than disks do.
But they’re far from perfect, as a FAST 15 paper Towards SLO Complying SSDs Through OPS Isolation by Jaeho Kim and Donghee Lee of the University of Seoul and Sam H. Noh of Hongik University points out:
In this paper, we show through empirical evaluation that performance SLOs cannot be satisfied with current commercial SSDs.
That’s a damning statement. Here’s what’s behind it.
The experiment
The researchers used a 128GB commercial MLC SSD purchased off-the-shelf and tested it either clean or aged. Aging is produced by issuing random writes ranging from 4KB through 32KB for a total write that exceeds the SSD capacity, causing garbage collection (GC).
They then tested performance in each mode using traces from the Umass Trace Repository. The traces were “replayed” generating real I/Os to the SSD for three workloads: financial; MSN; and Exchange.
Variables
In addition to clean and aged SSD performance, they tested each VM with its own partition on a clean SSD and running the workloads concurrently on a single partition on a clean SSD.
They repeated the tests using an aged SSD, to notable effect:

IO bandwidth of individual and concurrent execution of VMs.
One of the major effects of garbage collection is in the over provisioning space – the OPS of the title. While you can confine a single VM to a single partition the over provisioning space in an SSD is shared among all partitions – at least as far as the authors know.
Garbage collection
The authors ascribe the massive performance deltas to garbage collection. For those new to this issue the basic unit of flash storage is the page – typically a few KB – which are contained with blocks – typically anywhere from 128KB to 512KB.
But the rub is that entire blocks – not pages – have to be written, so as pages are invalidated there comes a time when the invalid pages have to be flushed. Once the number of invalid pages in a block reaches a threshold, the remaining good data is rewritten to a fresh block – along with other valid data – while the invalid data is flushed.
Erasing a block takes many milliseconds, so one of the key issues is tuning the aggressivenes of GC against the need to minimize writes so as to maximize flash’s limited life. This is but one of the many trade offs required for engineering the flash translation layer (FTL) that makes flash look like a disk.
Black box
But, as the researchers note, it is not possible to know exactly what is going on inside an SSD because the FTL is a proprietary black box.
Our work shows that controlling the SSD from outside the SSD is difficult as one cannot control the internal workings of GC.
GC is the likeliest explanation for the big performance hit when VMs share a partition. The GC process affects all the VMs sharing the partition, causing all of them to slow down. Here’s another chart from the paper:
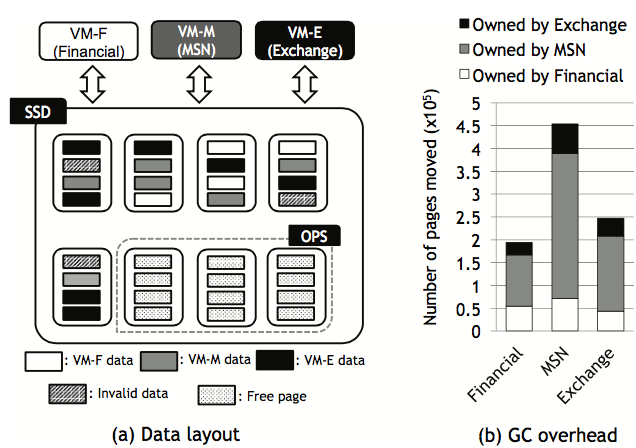
(a) Data layout of concurrent workloads in conventional SSD and (b) number of pages moved for each workload during GC.
Another variable is the degree of over provisioning in the SSD. Since flash costs money, over provisioning adds cost to the SSD. Over provisioning may be as little as 7% for consumer SSDs to as high as 35% for enterprise SSDs.
Yet another variable is the how the OPS is shared among partitions. If shared at the page level, much extra data movement – and reduced performance – is virtually assured. But again, that is under the control of the FTL, and it is hard to know how each vendor handles it.
The StorageMojo take
Flash storage has revolutionized enterprise data storage. With disks, I/Os are costly. With flash, reads are virtually free.
But as the paper shows, SSDs have their own issues that can waste their potential. Until vendors give users the right controls – the ability to pause garbage collection would be useful – SSDs will inevitably fail to reach their full potential.
My read of the paper suggests several best practices:
- Give each VM its own partition.
- Age SSDs before testing performance.
- Plan for long-tail latencies due to garbage collection.
- Pray that fast, robust, next-gen NVRAM gets to market sooner rather than later.
Comments welcome, as always.

Maybe we are too much hung up on the limited write endurance of SSDs. Now that prices have come down and SSDs are very competitive in the $-per-IO statistic, we should consider SSDs more like “consumablesâ€, with the added bonus that next year’s replacements will be faster and cheaper. Once we accept that, we can change the garbage collection algorithms to be more opportunistic, using periods of decreased activity to prepare for the next rush hour.
It is good idea to pause GC during day time and when IO are lean during night, let GC run and freshen up the disk for next day.
Part of the problem i have with this “test” is they use one of the smallest capacity drives you can get. SSD’s scale performance and hold their performance better the more flash chips they can address. 128 gigs won’t let any ssd strut it’s stuff.
Great article and it makes sense – if the back-end storage is just an array with faster drives in it and no granular controls the IO’s are going to blended and that’s going to cause issues.
One best practice you missed – run SSD’s in your server and reduce the IO blending by having granular acceleration policies.
As William said, using a 128GB SSD for this was not a great choice. Overprovisioning is where it’s at with SSDs and you can’t do it with such a low capacity. In addition the performance suffers already without aging due to the lowe amount of controller channel utilised. The current sweet spot is ~500GB (480-512) drives which cost well under $200 nowadays, it is pointless to use anything smaller. That way if you are really paranoid you can have an ultra fast RAID10 array with 500GB usable capacity (~250GB per disk with ~50% overprovisioning and 2 disks usable from the 4 total) for $600-$800 which is a pittance. The numbers above are ballpark, I didn’t care for the GB vs. GiB discrepancy, makes no difference to the core argument anyway.
The SSD used is small in order to enable the the wearout of the SSD in the first place but they also probably picked a disk that has lower design criteria and likely to have less over provisioning.
The over provisioning is a key criteria in the SSD as it affects both write amplification and through that endurance (WPD/TBW) and it also affects performance and most importantly the consistency of the performance. What one sees with lower OP drives is that performance drops off and becomes far less consistent when the disk is fully loaded for an extended period of time and doesn’t get any free time to run background erase on blocks to free them up. Then you get read and write IOs being blocked after erase operations which are lengthy and take a lot of power so reduce overall parallelization to make the SSD work within the 9W of power allotted to it.
Disable the garbage collection would achieve nothing if you don’t have enough over provisioning as you will not have free blocks to write into.
All that said, in any storage system, big or small if you want to give consistent performance to all shared users you make sure no single one of them and not all of them together fully use the resources of the device. Otherwise some or all of the users will go above the performance knee.
I didn’t think there was a lot of depth to this paper, but maybe just because we’ve been dealing with this issue in practice for several years! Tintri adapts how we write to the drive to minimize internal garbage collection for exactly this reason. Performance tanks (and internal write amplification kills the drive lifetime) once the drives start performing GC on random or interleaved writes. It is nice to see a per-VM solution being proposed though. 🙂
The best solution from a storage-vendor perspective would be to have the firmware be a little less transparent, so that the higher-level file system can more easily adapt to the demands of the media. But I agree with the conclusion of the paper that a “bare” SSD is unlikely to provide anywhere close to the peak performance advertised.
At the end the article you wrote:
“My read of the paper suggests several best practices:
Give each VM its own partition.
….”
I’ve thought about the nighmare to manually create hundreds on micro volumes on my storage… But I’ve remembered of the next upcoming VVol API “standard”.
My questions are:
– may “Give each VM its own partition” be correlated to vVol as a valid solution so ssd sla matter ?
– has vVol an unintentional benefit to improve SSD performance ? And, if yes,
– vVol support by AFA storage will be a key requirement to balance perfomance and easy to use?