
We want our data protected from device failures. When there is a failure we want to get our data back quickly. And we want to pay as little as possible for the protection and the restore. How?
Recent research by hyper-scale system managers – mostly Microsoft and Facebook engineers and scientists – has tried to answer that question. And the answers are way better than what we have today.
In XORing Elephants: Novel Erasure Codes for Big Data, authors Maheswaran Sathiamoorthy of USC, Alexandros G. Dimakis, Megasthenis Asteris, and Dimitris Papailiopoulos of [then] USC and now UT Austin, and Dhruba Borthakur, Ramkumar Vadali and Scott Chen of Facebook delve deeply into the issue.
RAID repair problem
Standard Reed-Solomon erasure codes aren’t well suited to hyperscale Hadoop workloads. Repair is big issue: both time and overhead.
Reed-Solomon codes suffer from an efficiency versus repair trade-off. Standard RAID5 or RAID6 needs a wide stripe for capacity efficiency, but a wide stripe makes the time to repair a failed disk much longer. Data has to be transferred from every other disk in the stripe, using up scarce disk I/Os and internal storage bandwidth.
Replication nation
To avoid this problem a decade ago scale out storage dispensed with Reed-Solomon codes in favor of simple double or triple replication. Because they used inexpensive disks rather than expensive arrays this was economical.
But exponential data growth has overwhelmed the ability of big web companies to build infrastructure fast enough and large enough to handle the tsunami of data. Something had to give. Triple replication was it.
But even triple replication isn’t enough for them. Since they can’t back up they need a level of redundancy that even RAID6 cannot approach.
These systems are now designed to survive the loss of up to four storage elements – disks, servers, nodes or even entire data centers – without losing any data. What is even more remarkable is that, as this paper demonstrates, these codes achieve this reliability with a capacity overhead of only 60%.
Xorbas the Geek
They examined a large Facebook analytics Hadoop cluster of 3000 nodes with about 45 PB of raw capacity. On average about 22 nodes a day fail, but some days failures could spike to more than 100.
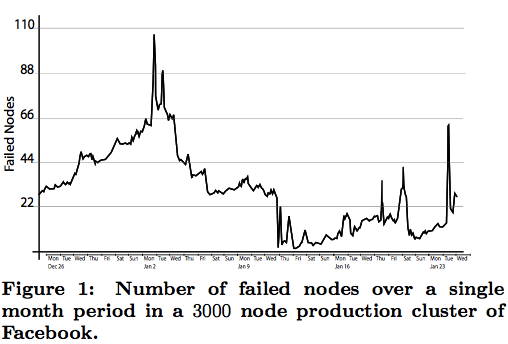
As Hadoop clusters are usually network bandwidth constrained – a few active disks can fill a 10Gb pipe – the network traffic generated by the failure repairs was non-negligible. An optimal storage solution would not only be capacity efficient, but also reduce network repair traffic.
The authors developed a new family of erasure codes called Locally Repairable Codes or LRCs that are efficiently repairable in disk I/O and bandwidth requirements. They implemented these codes in a new Hadoop module called HDFS–Xorbas and tested it on Amazon and within Facebook.
LRC test results found several key results.
- Disk I/O and network traffic were reduced by half compared to RS codes.
- The LRC required 14% more storage than RS, information theoretically optimal for the obtained locality.
- Repairs times were much lower thanks to the local repair codes.
- Much greater reliability thanks to fast repairs.
- Reduced network traffic makes them suitable for geographic distribution.
Here’s the table comparing replication, Reed Solomon and LRC. The (10, 6, 5) refers to data stripe blocks, parity blocks and local redundancy blocks respectively.

The StorageMojo take
Good news: WebCos will be able to store massive amounts of data more efficiently than ever before. Bad news: so will anyone else.
These codes increase pressure on enterprise storage vendors. The cheaper web storage makes CIOs more defensive when CFOs ask why their CapEx and OpEx are so high compared to WebCo. And that, in turn, forces CIOs to look beyond their current array vendors.
Creative destruction is too bad for the array vendors who’ve enjoyed a nice 15 year run, but it is necessary if we are to have a persistent digital culture. We’re still a long way from the longevity and easy access of a book, but this buys us more time to figure everything out.
A couple of the authors were kind enough to review the post and suggest changes to make it more accurate, which are now incorporated. Also you can access the project page for more details and a link to the code.
Commments welcome, as always. Do you think the web industry is doing enough to protect our data?

I believe some problems need to be resolved and forgotten so that we can move on to the next step. Reliable networked storage is one of them. That’s why I work on implementing erasure coding in http://ceph.com/ . I hope that, in the not so distant future, I’ll be able to buy storage, either at the nearest shop or online, that includes ceph instead of proprietary software that can’t be improved or fixed. “Creative destruction” as you so nicely put it, is the primary strength of Free Software : it dares resolve problems where proprietary software vendors make sure the problem remains to sell more and more licences.
Are you sure about that failed nodes number? I make that as 0.8%/month back-of-the-napkin. That’s 10%/year hardware failures. And that seems very very high to me.
-XC
The world leader in cloud storage writes 2 bytes for every 1 byte of customer input whereas the likes of MickySoft were doing 3x/4x replication. Data is sharded across N hosts (actually disks) and they only need half of the hosts available to reassemble. The cost is of course in CPU (to do the transform) and latency (fetch shards over network). I think something more like 7:12 would be a better ratio but they would have to do a better job of scrubbing/repair.
There are a couple of commercial products out there but they charge an unholy amount of money for no good reason. Maybe Ceph will get there but I think Gluster will have an implementation first.
Looks like Facebook is really serious about their erasure coding. Last week I saw some more erasure codes from the Facebook stable (this time with folks from Berkeley) at the Usenix Hot-storage workshop in San Jose. These erasure codes also did better repair, but the presenter claimed that they didn’t have any additional storage overhead (which I thought was cool) than our good old Reed-Solomon. There were some additional measurements of the Facebook system presented than what you have described in your post (I apologize that I haven’t read either paper yet though). Way to go Facebook, carry on..