
In response to Building fast erasure coded storage, alert readers Petros Koutoupis and Ian F. Adams noted that advanced erasure coded object storage (AECOS) isn’t typically CPU limited. The real problem is network bandwidth.
It turns out that the same team that developed Hitchhiker also looked at the network issues. In the paper A Solution to the Network Challenges of Data Recovery in Erasure-coded Distributed Storage Systems: A Study on the Facebook Warehouse Cluster, K. V. Rashmi1, Nihar B. Shah1, and Kannan Ramchandran of UC Berkeley, and Dikang Gu, Hairong Kuang, and Dhruba Borthakur, of Facebook, looked at the problem of network overhead during data recovery.
Replicas vs Reed Solomon erasure codes
Recovering data from replicas is easy: copy it. Since three copies is the norm, the recovery process only minimally impacts operations.
With RS codes though, there is no replica. For a system that encodes k units of data with r parity units, all k data is recoverable from any k of (k+r) units.
Thus an HDFS system, such as Facebook commonly uses, that puts the data into 10 data units and 4 parity units, can survive the loss of 4 drives, servers, or even data centers – depending on how the units are distributed. That’s way better than RAID 5 or 6 on legacy RAID arrays.
But you see the problem: during data recovery the system has to read and transfer k units. And the units can be quite large – depending on the AECOS configuration – typically up to 256MB. In that case the system would transfer 2.56GB to recover one unit.
Of course, if it is a server failure, there will be many units to recover, bringing the typical top-of-rack switch to its knees. Here’s the data from a Facebook facility:
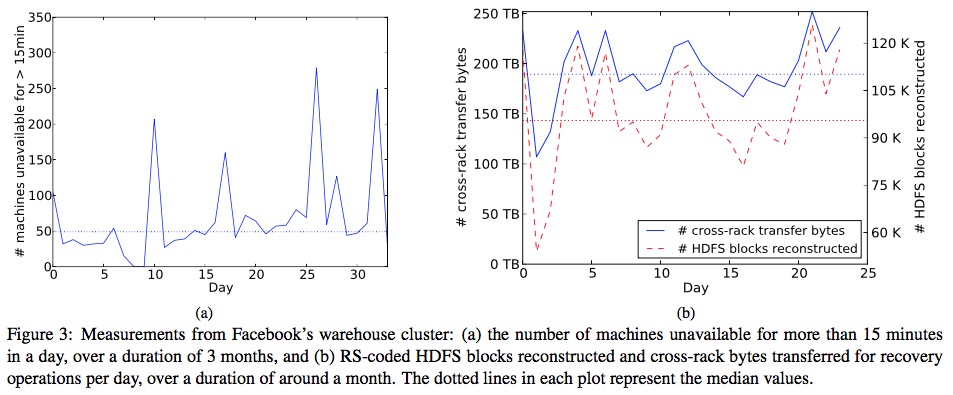
Click to enlarge.
Piggyback on RS codes
As in the Building fast erasure coded storage post, the team added a one-byte stripe that saves around 30% on average in read and download volume for single block failures. With 256MB block sizes, recovery speed is limited by network and disk bandwidth, so the reduction should significantly reduce recovery time.
Added bonus: because recovery is quicker – and disk failures are correlated – the piggybacked RS code should be even more reliable than a straight RS code.
The StorageMojo take
Much appreciate the readers who pointed out the critical role of bandwidth in AECOS systems. I hope this discussion helps address my oversight.
Courteous comments welcome, of course.

Robin,
Thank you for the followup. Correct me if I am wrong but the cited Facebook study only focuses on single site network limitations. Take the case of Cleversafe (now IBM Cloud Object Storage). Their entire model is based on the idea that storage servers can live in one or more racks in one or more data centers in one or more sites around the globe. Network throughput is even more of an issue here. For “rebuild” operations, you are only as fast as your slowest speed.
The best part of how some distributed scale-out storage solutions function is that during read operations, you only need to read from the minimum amount of slices to regenerate the original object. For example, in a 12-wide system where 4 may be considered the parity. You only need to access 8 of the 12 servers and if implemented correctly, you should be accessing ONLY the 8 fastest servers of the entire distributed network.
Echoing Petros, thanks for the follow up!
I’d add though, that theres a tradeoff to be had by only requesting the minimum number of fragments to reconstruct.
Using the example Petros gave with 8/12. On the one hand, in an ideal environment you reduce the amount of traffic needed, on the other, we rarely live in such clean environments and if even one of those fragments is slow in returning, you slow down your entire request. You may actually service a request faster by requesting all 12 just using the first 8 returned to rebuild on the fly as the likelihood that 1/3 of your servers is slow at that moment is much lower, though now you have a tradeoff of sapping more bandwidth to accomplish this. Its a tricky balance to get right, further complicated by the peculiarities of various setups and architectures….